-
[Paper Review] MobileNetV2: Inverted Residuals and Linear Bottlenecks (Sandler et al., 2019)Paper Review/Model Architectures 2026. 2. 6. 03:02
MoblieNetV1이 Depthwise Separable Convolution을 이용해 경량화의 가능성을 증명했다면, V2는 그 구조를 한 단계 더 진화시켜 '효율'과 '성능'이라는 두 마리 토끼를 어떻게 더 완벽하게 잡을 것인가에 대한 해답을 제시한다.
논문의 Abstract에서는 저자들이 MobileNetV2가 단순한 분류(Classification)를 넘어 객체 탐지(SSDLite)와 시멘틱 세그멘테이션(Mobile DeepLabv3) 등 다양한 테스크에서 당시 최고 수준(State-of-the-art)의 성능을 달성했음을 강조한다.
MobileNetV1에서 V2로 넘어갈 때, 가장 핵심적인 변화는 두 가지이다. 하나는 Inverted Residual(역잔차 구조)이고, 다른 하나는 Linear Bottleneck(선형 병목)이다. 기존의 상식을 뒤집는 이 구조를 통해 저자들은 모델의 크기와 연산량을 줄이면서도 정보의 손실을 획기적으로 막아냈다. 특히 메모리 사용량을 최소화하도록 설계되어 실제 모바일 하드웨어 가속기에서 구동하기에 최적화되었다는 점이 핵심이다.
그렇다면 MobileNetV2에서 제안한, Inverted Residual with Linear Bottleneck이라는 새로운 레이어 모듈은 어떻게 작동할까?
보통의 Residual Block은 '넓은 채널 -> 좁은 채널 -> 넓은 채널' 순서로 연결되지만, MobileNetV2는 이를 뒤집어 '좁은 채널 -> 넓은 채널 -> 좁은 채널' 순서로 처리한다. 먼저 저차원의 압축된 데이터를 받아 높은 차원으로 확장(Expansion)시킨 뒤, 가벼운 Depthwise Convolution으로 특징을 걸러내고, 다시 저차원으로 투영(Projection)시키는 방식이다.
이 모듈은 단순히 연산량만 줄이는 것이 아니다. 이 구조는 Inference 과정에서 거대한 중간 텐서(Intermediate Tensor)를 메모리에 통째로 올릴 필요가 없게 만든다.
임베드디 하드웨어는 보통 작지만 매우 빠른 '캐시 메모리'를 가지고 있는데, MobileNetV2의 설계는 이 캐시 메모리를 최대한 활용하여 메인 메모리(DRAM) 접근을 줄여준다. 이는 곧 전력 소모 감소와 발열 억제, 그리고 속도 향상으로 직결된다.
Preliminaries, discussion and intuition
1. Depthwise Separable Convolutions
먼저, V2를 이해하기 위해 V1의 근간이었던 Depthwise Separable Convolution을 완벽히 짚고 넘어가야 한다. 해당 내용은 아래 링크에 "MobileNetV1"에 자세히 설명되어있다.
MobileNetV12. Linear Bottlenecks
Manifold of Interest
우리가 다루는 이미지 데이터는 픽셀 수만큼의 거대한 차원(예: 224x224x3)을 가지고 있지만, 실제로 유의미한 정보(고양이인지, 강아지인지 등)는 그보다 훨씬 낮은 차원의 공간에 모여 있다. 이를 Manifold of Interest라고 한다.저자들은 신경망의 각 레이어에 흐르는 데이터(Activation Tensor) 역시 이 낮은 차원의 매니폴드에 임베딩될 수 있다고 가정한다. 즉, 128개의 채널을 쓰고 있더라도 실제 정보는 그보다 훨씬 적은 수의 차원만으로도 충분히 표현이 가능하다는 의미이다.
하지만 여기서 문제가 발생한다. 딥러닝의 필수 요소인 ReLU 때문이다. ReLU는 0보다 작은 값을 모두 지워버린다.
저차원에서 ReLU를 사용할 때를 보면, 만약 우리가 정보를 아주 꽉꽉 압축해서(Low-dimensional) 전달하고 있는데 거기다 대고 ReLU를 적용한다면 어떻게 될까? 0 이하의 값들이 잘려 나가면서, 정보가 담긴 매니폴드의 일부가 완전히 파괴(Collapse)되어 버린다.
반대로, 고차원에서 ReLU를 사용할 때도 생각을 해보자. 채널 수가 아주 많은 고차원 공간에서 ReLU를 사용하면, 설령 몇몇 채널에서 정보가 잘려 나가더라도 다른 채널들에 그 정보가 살아남아 있을 확률이 높다.

위 그림을 봐보면, 차원이 낮을 때(n=2,3)는 ReLU를 거치면서 원래의 나선형 모양이 뭉개지고 정보가 손실되지만, 차원이 높을 때(n=15, 30)는 ReLU를 거쳐도 다시 원래 모양을 복원할 수 있을 만큼 정보가 잘 보존된다.
이 문제를 바탕으로 두 가지 결론을 내린다.
- ReLU를 통과한 후에도 정보가 살아남아 있다면, 그것은 사실상 선형 변환(Linear Transformation)을 한 것과 다름없다.
- ReLU가 정보를 온전히 보존하려면, 입력 매니폴드가 입력 공간의 저차원 부분 공간에 있어야 한다.(즉, 충분히 확장된 상태여야 한다.)
그래서 탄생한 것이 Linear Bottleneck이다.
- 데이터가 압축된 좁은 층(Bottleneck)에서는 정보 손실을 막기 위해 비선형 활성화 함수(ReLU)를 아예 제거하고 선형 연산만 수행한다.
- 대신, 그 앞 단계에서 채널을 대폭 확장(Expansion)시킨 뒤 거기서만 ReLU를 사용하여 비선형 특징을 추출한다.
즉, Linear Bottleneck은 좁은 층에서는 ReLU를 빼서 정보를 보존하고, 넓은 층에서만 ReLU를 써서 복잡한 특징을 배운다.는 전략이다.
3. Inverted Residuals
우리가 잘 아는 전통적인 ResNet의 잔차 구조(Residual Block)는 넓게 -> 좁게 -> 넓게의 형태를 띤다. 즉, 많은 채널(정보)을 가진 상태에서 연산을 위해 잠시 줄였다가(Bottleneck), 다시 늘려서 다음 층으로 전달한다.
하지만 MoblieNetV2는 이를 정반대로 뒤집었다. 좁게 -> 넓게 -> 좁게 구조이다.
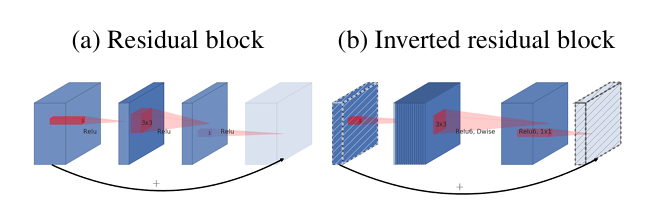
- Shorcut의 위치 : V2는 정보가 압축된 좁은 채널(Bottleneck)끼리 직접 연결한다.
- 이유 : 저자들은 "진짜 중요한 정보는 좁은 병목 층에 다 담겨 있다"고 믿었다. 확장 층(Expansion Layer)은 단순히 비선형 변환(ReLU)을 잘 수행하기 위한 '구현상의 도구'일 뿐이므로, 핵심 정보가 흐르는 통로는 좁은 구간끼리 이어주는 것이 맞다는 논리이다.
그렇다면 이 '거꾸로 뒤집기'가 모바일 환경에서 어떤 이점을 가져올까?
기본 구조는 넓은 채널끼리 연결하기 때문에, 데이터를 잠시 보관해야 하는 '메모리 점유율'이 매우 높았다. 반면 MobileNetV2는 아주 좁은 통로(Bottleneck)만 메모리에 유지하고, 중간의 확장된 데이터는 필요한 순간에만 잠깐 쓰고 버릴 수 있다. 덕분에 메모리가 적은 모바일 칩셋에서도 훨씬 큰 네트워크를 돌릴 수 있게 된 것이다. 즉, 메모리 절약 측면에서 Invverted가 이점을 가져온다고 볼 수 있다.
블록의 연산 비용을 살펴보면, 다음과 같다.
$$h \cdot w \cdot d \cdot t(d + k^2 + d')$$- $t$ : 확장 비율(Expansion Factor, 보통 6)
- $d$ : 입력 채널, $d'$ : 출력 채널
V1에 비해 $1\times 1$ 연산이 하나 더 추가되었음에도 불구하고($d$를 $td$로 늘리는 과정), 입력과 출력 채널($d, d'$) 자체가 매우 작게 유지되기 때문에 전체적인 연산량과 파라미터 수는 여전히 매우 낮게 유지된다.
정리하자면, Inverted Residual은 좁은 층에서 정보를 유지하고, 넒은 층에서 연산하며, 다시 좁은 층으로 결과를 보낸다.는 효율성의 극치이다. 아래 테이블은 이 과정을(Expansion -> Deptwise -> Projection)의 3단계로 정리하여 보여준다.

4. Information flow interpretation
용량(Capacity) vs 표현력(Expressiveness)
전통적인 CNN 레이어에서는 이 두 가지가 하나로 뭉쳐있었다. 하지만 MobileNetV2의 블록은 이를 명확히 나눈다.- 용량(Capacity) : 블록의 입력과 출력인 Bottleneck 레이어를 의미한다. 네트워크가 다음 층으로 전달할 수 있는 '정보의 양'이 얼마나 되는지를 결정한다. 즉, 병목(Bottleneck)이 얼마나 넓으냐가 곧 네트워크의 용량이 된다.
- 표현력(Expressiveness) : 블록 내부의 확장 층(Expansion Layer)과 비선형 변환(ReLU)을 의미한다. 입력받은 정보를 얼마나 복잡하고 정교하게 가공(Transformation)할 수 있는지를 결정한다.
그렇다면 왜 이 분리가 어떤 이점을 가져오는 것일까?
기존의 표준 합성곱이나 V1의 분리 합성곱은 출력 채널 수($d_j$)를 정하면 용량과 표현력이 동시에 결정되어 버렸다. 하지만 V2는 다르다.- 확장 비율(Expansion Ratio, $t$)의 조절 : V2는 Bottleneck의 크기(용량)는 유지한 채, 내부의 확장 비율($t$)만 조절해서 '표현력'만 따로 키울 수 있다.
- 유연한 설계 : 만약 확장 비율이 1보다 작으면 전통적인 ResNet과 비슷해지고, 0이 되면 아무것도 하지 않는 항등 함수(Identity funtion)가 된다. 저자들은 실험을 통해 확장 비율이 1보다 큰 경우(보통 6배)가 정보를 처리하는 데 가장 유용하다는 것을 찾아냈다.
정리하자면, Bottleneck과 Expansion을 분리하여 모델이 얼마나 많은 정보를 가질지와 표현력을 각각 독립적으로 최적화할 수 있게 된 것이다.
Model Architecture
앞서 설명한 Inverted Residual 블록이 구체적으로 어떤 순서로 연산되는지, 그리고 전체 네트워크가 어떤 레이어들로 구성되는지를 살펴보자.
Bottleneck Residual Block
저자들은 블록 하나가 데이터를 어떻게 변형시키는지 아래 테이블을 통해 정의했다.
- Expansion($1\times 1 Conv + ReLU6) : 입력 채널 $k$를 확장 계수 $t$를 곱해 $tk$로 불린다. 여기서 ReLU6를 사용한다는 점이 독특한데, 이는 값을 0~6 사이로 제한하여 저정밀도(Low-Precision) 연산 시 수치적 안정성을 높이기 위함이다.
- Depthwise Convolution($3\times 3$ DW + ReLU6) : 확장된 채널 상태에서 공간적 특징을 추출한다.
- Projection($1\times 1$ Conv + Linear) : 다시 원래의 좁은 채널로 압축한다. 이때 비선형 활성화 함수를 쓰지 않는 'Linear' 방식을 택해 정보 손실을 막는다.
전체 네트워크 구성

- 첫 번째 레이어는 표준 $3\times 3$ Conv으로 시작한다.
- 그 뒤로 19개의 Residual Bottleneck Layer가 이어진다.
- 표의 $n$은 동일한 레이어를 몇 번 반복하는지를, $s$는 스트라이드를 의미한다.
- 마지막에 $1\times 1$ 합성곱을 통해 채널을 1280까지 확 늘린 뒤, Average Pooling을 거쳐 분류(Classification)를 수행한다.
여기서 재미있는 점은 V1과 달리 마지막 $1\times 1$레이어의 채널 수가 매우 크다(1280)는 것이다. 이는 앞단에서 효율적으로 아낀 연산 자원을 마지막 특징 추출 단계에 집중 투자하여 정확도를 끌어올리려는 전략이다.
메모리 효율성
아래 테이블을 보면, MobileNetV2가 왜 모바일 하드웨어 친화적인지를 'Materialized Memory'수치로 증명한다.
V1이나 ShuffleNet은 중간 연산 과정에서 큰 텐서를 메모리에 들고 있어야 하는 경우가 많다. 하지만 V2는 Inverted Residual 덕분에 병목(Bottleneck) 부분의 작은 데이터만 메모리에 유지하면 된다. 표를 보면 $112 \times 112$ 해상도에서 V1은 1600Kb가 필요할 때, V2는 단 400Kb만 필요하다. 메모리 점유율을 4배나 줄인 것이다. 이는 캐시 메모리가 적은 모바일 프로세서에서 엄청난 속도 향상을 가져온다.
Hyperparameter와 Trade-off
V1과 마찬가지로 Width Multiplier($\alpha$)와 Resolultion Multiplier($\rho$)를 제공한다.- $\alpha$ = 1.0, $224\times 224$ 해상도 기준 약 3억 번의 연산(MAdds)과 3.4M개의 파라미터를 가진다.
- 특이한 점은 $\alpha < 1$인 아주 작은 모델을 만들 때, 성능 저하를 막기 위해 가장 마지막 합성곱 레이어에는 $\alpha$를 적용하지 않고 채널을 유지했다는 점이다.
Experiment
아래 표는 ImageNet 분류 실험이다. 이 실험에서 저자들은 정확도는 높이고, 연산량과 모델 크기는 줄였다는 것으르 숫자로 증명한다.
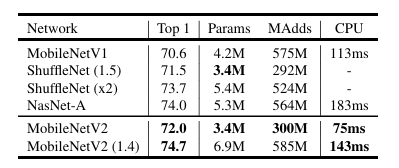
- V1 vs V2 : MobileNetV2는 V1보다 정확도는 약 1.5% 더 높으면서도, 파라미터 수는 약 3.4M으로 더 적고 연산량도 크게 줄였다.
- 당시 경쟁 모델이었던 ShuffleNet 등과 비교했을 때도, 동일한 연산 자원 대비 가장 높은 정확도를 기록하며 '모바일 최강자'임을 입증했다.
Object Detection
객체 탐지에서도 MobileNetV2는 엄청난 효율을 보여준다.
SSDLite 제안 : 기존의 SSD(single Shot Detector) 연산을 MobileNetV2의 철학에 맞게 Depthwise Separable 방식으로 바꾼 SSDLite를 선보였다.

기존 YOLOv2 대비 연산량은 약 10배, 모델 크기는 20배나 작으면서도 정확도(mAP)는 대등하거나 더 높았다. 이는 모바일 기기에서 실시간 객체 탐지가 훨씬 수월해졌음을 의미한다.
Segmentation: Mobile DeepLabv3
이미지 내의 물체 영역을 픽셀 단위로 따내는 시멘틱 세그멘테이션에서도 성과를 낸다.
- 가장 무거운 모델 중 하나인 DeepLabv3를 MobileNetV2 기반으로 경량화를 했다.
- 연산량은 엄청나게 줄이면서도 성능 저하는 최소화하여, 모바일 환경에서도 정교한 이미지 편집이나 AR 필터 같은 기능이 가능함을 보여주었다.
하이퍼파라미터 트레이드오프
저자들은 $\alpha$를 조절함에 따라 모델이 얼마나 유연하게 변하는지도 강조한다.
모델을 깍아내릴 때(저사양 기기용) 성능이 급격히 망가지지 않고 아주 완만하고 예측 가능하게 변한다는 점을 보여준다. 이는 개발자가 목표 기기의 사양에 맞춰 모델을 커스터마이징하기 매우 유리하다는 의미이다.
Conclusion
MobileNetV2는 경량화 네트워크 설계에 있어, "정보를 어떻게 다루어야 하는가?"에 대한 정답을 제시했다. 저자들은 단순히 연산량을 줄이는 기술적인 접근을 넘어서, Inverted Residual과 Linear Bottleneck이라는 개념을 통해 신경망 내부의 정보 흐름을 이론적으로 정립했다. 그 결과, MobileNetV2는 정확도 향상, 메모리 최적화, 측면에서 매우 좋은 성과를 거두었다.
하지만,현재는 Quantization을 연구하므로, Quantization 관점에서 바라보면, 정말 까다로운 모델이라고 생각한다. 그 이유는 다음과 같다.
- V2는 이미 설계 단계에서 정보의 중복을 극단적으로 제거했다. Bottleneck은 말 그대로 정보가 꽉 차 있는 상태이다. 여기에 비트 수를 줄여 양자화를 한다? 모델이 버틸 힘이 없어 정확도가 뚝 떨어질 것 같다.
- V2의 핵심은 Shortcut이다. Shortcur 양자화 시 두 경로의 데이터 범위를 맞춰야 하는 번거로움이 발생할 것 같다. 게다가 Linear Bottleneck 때문에 활성화 값의 범위가 특정되지 않고 넓게 퍼지는 경향이 있어, 이를 8비트 혹은 4비트로 예쁘게 담아내는 것이 매우 어려울 것 같다.
'Paper Review > Model Architectures' 카테고리의 다른 글