-
[Paper Review] Token Merging: Your ViT But Faster (ICLR, 2023)Paper Review/Model Compression 2026. 3. 14. 14:50
양자화가 모델의 가중치나 활성화 값의 정밀도를 낮춰 메모리와 연산량을 줄인다면, 이 논문은 트랜스포머가 처리하는 데이터의 단위인 '토큰(Token)'의 개수 자체를 줄여버림으로써 연산 병목을 해결하고자 하는 아주 직관적인 방법론을 제시한다.
트랜스포머 모델, 특히 컴퓨터 비전 분야에서 널리 쓰이는 ViT(Vision Transformer)는 성능은 대단히 훌륭하지만, 연산량이 너무 많다는 치명적인 단점이 존재한다. 이 논문에서는 새롭게 모델을 처음부터 다시 학습시킬 필요 없이, 기존에 잘 학습된 ViT 모델의 처리 속도를 획기적으로 높일 수 있는 '토큰 병합(ToMe)'이라는 아주 간단하면서도 강력한 방법을 제안하고 있다.
이 기술의 핵심 아이디어는 트랜스포머 층을 통과할 때마다 서로 비슷한 의미나 정보를 담고 있는 토큰들을 점진적으로 하나로 합쳐버리는 것이다. 이때 굉장히 가볍고 범용적인 매칭 알고리즘을 사용하는데, 이것이 기존의 경량화 기법들과는 비교되는 강력한 무기가 된다. 기존에는 불필요해 보이는 토큰을 단순히 잘라내어 버리는 가지치기(Pruning) 기법이 많이 쓰였는데, ToMe는 이 가지치기만큼이나 속도가 빠르면서도 정보 자체를 버리는 것이 아니라 합치는 것이기 때문에 정보 손실이 적어 정확도는 훨씬 높다는 놀라운 장점을 가지고 있다.
논문의 저자들이 말하는 가장 매력적인 부분인 이 기술을 이미 다 만들어진 상용 모델에 바로 가져다 써도 엄청난 효과를 본다는 점이다. 아주 무거운 최첨단 모델인 ViT-L이나 ViT-H를 이미지 데이터에 적용했을 때 처리 속도를 무려 2배나 끌어올렸다. 비디오 데이터에서는 처리 속도를 2.2배나 높이면서도, 정확도 하락은 겨우 0.2%에서 0.3% 수준으로 방어해냈다. 모델의 파라미터를 건드리지 않고 이 정도의 효율을 낸다는 것은 실제 산업 환경에 배포할 때 엄청난 이점이 된다.
이 방법은 모델의 학습 과정에 직접 적용하는 것도 당연히 가능하다. 실제로 비디오 데이터를 활용한 학습에 적용해보니, 훈련 속도 자체가 2배나 빨라지는 실질적인 효과를 얻었다고 한다. 게다가 학습 단계부터 이 병합 방식을 모델이 적응하도록 만들면 정확도 하락을 더욱 최소활 수 있어서, 오디오 데이터를 처리할 때도 속도를 2배 높이면서 성능 하락은 단 0.4%에 불과한 아주 훌륭한 결과를 보여주었다.
이들이 모델 내부를 정성적으로 분석한 결과오 아주 흥미롭다. 이 알고리즘이 아무 토큰이나 막 합치는 것이 아니라, 예를 들어 강아지 사진이라면, 강아지의 털이나 다리처럼 같은 객체를 구성하는 부분들은 하나의 토큰으로 묶어내는 것을 확인했다. 심지어 비디오 영상에서는 여러 프레임에 걸쳐서도 동일한 물체의 토큰들이 잘 병합되는 것을 볼 수 있다.
Introduction
처음 자연어 처리(NLP) 분야에서 대성공을 거둔 트랜스포머 기술이 컴퓨터 비전 분야로 넘어와 '비전 트랜스포머(ViT)'라는 이름으로 등장했을 때, 학계는 엄청난 발전 속도에 열광했다. 하지만 시간이 지나면서 비전 분야는 순수한 형태의 ViT보다는 Swin, MViT, LeViT처럼 이미나 영상 처리에 특화된 구조를 섞어 만든 '하이브리드 모델'들이 지배하게 되었다. 이유는 단순하다. 바로 '효율성' 때문이다. 비전 데이터에 딱 맞는 특수한 구조(Inductive bias)를 추가하면 더 적은 연산량으로도 훨씬 좋은 성능을 낼 수 있기 때문이다.
그럼에도 불구하고 연구자들은 아무것도 섞이지 않은 순수한 '바닐라 ViT'에 여전히 큰 미련을 가지고 있다. 바닐라 ViT는 단순한 행렬 곱셈으로 이루어져 있어 실제 계산량 대비 하드웨어에서의 동작 속도가 꽤 빠르고, MAE(Masked Autoencoders) 같은 강력한 자가 지도 학습 기법을 적용하기에도 아주 훌륭했다. 게다가 데이터의 형태를 가리지 않는 트랜스포머의 본질적인 특성 덕분에 이미지, 비디오, 심지어 오디오까지 큰 수정 없이 적용할 수 있고, 데이터가 엄청나게 많아질수록 성능이 끝없이 올라간다는 어마어마한 잠재력을 가지고 있었기 때문이다.
하지만 문제가 하나 있었다. 이렇게 강력한 순수 ViT 모델의 크기를 키우고 막대한 데이터를 학습시킨 최고 수준의 모델들을 실제 환경에서 굴리거나 재현하는 건 연산량 측면에서 너무나 큰 고통이었다. 그래서 최근 학계에서는 연산량을 줄이기 위해 '토큰 가지치기(Token Pruning)'라는 기술에 주목하기 시작했다. 데이터 입력과 무관하게 동작하는 트랜스포머의 특성을 이용해, 연산 중간에 덜 중요해 보이는 토큰들을 아예 잘라내 버려서 모델을 가볍게 만드는 방식이다.
하지만 저자들은 이 가지치기 방식에 여러 가지 치명적인 단점이 있다고 지적한다. 우선 정보를 아예 버리는 방식이다 보니 일정 수준 이상으로 토큰을 줄이면 성능이 뚝 떨어져 버린다. 게다가 이 방식을 제대로 사용하려면 모델을 처음부터 다시 학습시켜야 하는 번거로움이 있고, 입력되는 이미지마다 잘라내는 토큰의 개수가 달라져서 여러 데이터를 한 번에 처리하는 '배치(Batch) 연산'이 사실상 불가능하다. 이는 곧 실제 학습 속도를 높이는 데에는 별 도움이 안된다는 의미이다.
그래서 이 논문은 가지치기의 한게를 완벽하게 극복할 '토큰 병합(Token Merging, ToMe)'이라는 아주 우아한 해결책을 제시하게 된 것이다. 덜 중요한 것은 '버리는' 대신, 비슷하고 중복되는 의미를 가진 토큰들을 똑똑하게 '합쳐버리는' 방식을 택했다. 저자들은 특별히 고안한 가벼운 매칭 알고리즘 덕분에, 이 병합 과정은 기존의 무식하게 잘라내는 가지치기만큼이나 연산 속도가 빠르면서도 정보 손실을 막아 정확도는 훨씬 높게 유지할 수 있다.
가장 놀라운 점은 이 기술의 범용성이다. 이미 다 학습된 거대한 모델에 추가 학습 없이 그냥 툭 얹어 놓기만 해도 속도를 비약적으로 높여주고, 반대로 모델을 처음 학습시키는 과정에 적용하면 전체 학습 시간을 무려 반토막 내주기도 한다.
Related Work
Efficient Transformers
트랜스포머 구조가 자연어 처리(NLP)와 비전 분야를 휩쓸면서, 이 무거운 모델을 어떻게든 가볍고 빠르게 만들려는 시도는 꾸준히 있어 왔다. 어떤 연구자들은 연산의 핵심인 Attention 메커니즘 자체를 수학적으로 가볍게 고치려고 했고, 또 다른 사람들은 불필요해 보이는 어텐션 헤드(Head)나 특징(Feature)을 솎아내기도 했다. 앞선 서론에서 말했던 것처럼, 아예 비전 데이터 처리에 유리한 특화된 구조를 모델에 억지로 집어넣는 연구들도 이 흐름의 연장선에 있다. 하지만 이 논문의 저자들은 조금 다른 길을 선택한다. 모델의 구조를 복잡하게 뜯어고치거나 특정 도메인에 얽매이는 대신, '이미 잘 만들어져 있는(Existing) 바닐라 ViT 모델'의 토큰들을 영리하게 병합하여 속도를 높이는 데 집중한 것이다. 그 결과, 추가적인 학습이나 복잡한 구조 변경 없이도 기존의 특화된 하이브리드 모델들과 맞먹는 훌륭한 속도-정확도 균형을 달성할 수 있었다.Token Reduction, Pruning
트랜스포머는 입력되는 토큰의 개수가 몇 개든 유연하게 처리할 수 있다는 장점이 있어서, 중요하지 않은 토큰을 중간에 과감히 잘라내려는 연구가 아주 활발했다. 하지만 여기서 저자들은 기존 가지치기 방식들의 치명적인 약점을 아주 날카롭게 찌르고 있다. 가장 큰 문제는 기존 방법론들이 그 효과를 보려면 반드시 모델을 처음부터 '재학습(training)'시켜야 한다는 점이다. 게다가 더 큰 현실적인 문제가 있는데, 대부분의 가지치기 기법들은 입력되는 이미지나 문장의 복잡도에 따라 살아남는 토큰의 수가 제각각 달라지는 '동적(Dynamic)'인 방식을 취했다. 이미지마다 토큰 길이가 달라지니, 여러 이미지를 한번에 묶어서 GPU에 올리는 '배치(Batch) 연산'이 사실상 불가능해지는 것이다. 그래서 기존 연구들은 실제 학습을 할 때 토큰을 진짜로 없애는 대신 그냥 없는 셈 치는 '마스킹(Masking)' 처리만 하는 꼼수를 썼는데, 결국 이 때문에 메모리만 차지하고 실제적인 속도 향상은 얻지 못했다. 반면, 우리의 ToMe는 입력 데이터와 무관하게 정해진 수만큼 토큰을 줄일 수 있어서 배치 연산이 완벽하게 가능하고, 덕분에 추론뿐만 아니라 학습 단계에서도 진짜 '실질적인 속도 향상(real-world speed-ups)'을 이뤄넀다.Combining Tokens
토큰을 단순히 잘라내어 버리는 것이 아니라, '결합(Combineing Tokens)'하려는 시도들이다. 사실 토큰을 합치자는 아이디어 자체가 이 논문이 처음은 아니였다. 가지치기를 하고 남은 찌꺼기 토큰들을 하나로 뭉쳐보려는 시도도 있었고, 의미론적 분할(Semantic Segmentation)을 위해 비슷한 토큰끼리 그룹을 지어보는 연구(GroupViT)도 있었따. 또 신경망을 위해 비슷한 토큰끼리 그룹을 지어보는 연구(GroupViT)도 있었다. 또 신경망(MLP)을 추가로 달아서 토큰 수를 압축하려는 시도들도 있었다. 이 중에서 ToMe와 철학적으로 가장 비슷한 접근을 한 것은 'Token Pooling'이라는 기법인데, 이 방법은 전통적인 K-means 군집화 알고리즘을 사용해서 토큰들을 묶어 냈다. 하지만 K-평균 알고리즘 자체가 매번 반복 연산을 해야 해서 너무 느린 데다가, 결정적으로 이미 다 학습된 상용 모델에 추가 학습 없이 바로 가져다 쓸 수가 없다는 뼈아픈 한계가 존재했다.Token Merging
이 기술의 최종 목표는 이미 다 만들어진 기존 ViT 모델에 토큰 병합 모듈을 쏙 집어넣어서, 추가 학습 없이도 처리량(Throughput)을 확 높이는 것이다.
Strategy
트랜스포머는 여러 개의 층(Block)으로 겹겹이 쌓여있는데, 저자들은 각 블록을 통과할 때마다 정확히 'r'개의 토큰을 병합해서 줄이기로 했다. 여기서 아주 중요한 포인트는 이 'r'이 비율(%)이 아니라 절대적인 '개수'라는 점이다. 만약 모델이 L개의 블록으로 이루어져 있다면, 전체 네트워크를 다 통과하고 나면 총 'r x L'개의 토큰이 점진적으로 줄어들게 되는 것이다. 'r' 값을 크게 잡으면 토큰이 많이 줄어들어 속도는 엄청나게 빨라지겠지만, 그만큼 정보가 많이 섞여서 정확도는 떨어질테고, 반대로 작게 잡으면 속도 향상은 적지만 정확도는 잘 유지될 것이다. 즉, 이 'r'이라는 값 하나로 속도와 정확도 사이 Trade-off를 아주 직관적으로 조절할 수 있다.이 '고정된 개수'를 줄인다는 것은 실용적인 측면에서 어마어마한 장점을 가지고 온다. 앞서 관련 연구를 설명할 때 기존 가지치기(Pruning) 기법들은 이미지의 내용에 따라 잘라내는 토큰의 수가 계속 변한다고 했다. 그렇게 되면 이미지마다 길이가 달라져서 여러 장의 이미지를 동시에 GPU에 올려 계산하는 배치(Batch) 연산이 불가능해진다. 하지만 ToMe는 어떤 이미지가 들어오든 무조건 정해진 개수(rL)만큼만 토큰을 줄이기 때문에, 배치 연산이나 학습을 아무런 문제 없이 완벽하게 수행할 수 있다.
Token Similarity
그렇다면, 이 병합 모듈을 트랜스포머 블록의 '어디에' 끼워 넣는 것이 가장 좋을까? 저자들은 어텐션(Attention) 연산을 수행한 직후, 그리고 다층 퍼셉트론(MLP)으로 넘어가기 바로 그 '중간'에 이 모듈을 배치했다. 기존의 많은 연구가 블록이 시작하자마자 무언가를 덜어내려 했던 것과는 대조적이다. 이렇게 중간에 배치한 이유는 두 가지이다. 첫째, 어텐션 연산을 한 번 거치면서 토큰들끼리 서로 정보를 충분히 교환하게 만든 뒤 병합을 해야 정보 손실이 적기 때문이고, 둘째, 어텐션 내부에서 계산된 유용한 특징(Feature) 값들을 활용해서, '어떤 토큰을 합칠지' 결정하기 위해서이다.그럼 대체 어떤 토큰끼리 합쳐야 할까?
즉, 두 토큰이 비슷하다(Token Similarity)는 것을 어떻게 정의할 것인가 하는 문제이다.가장 단순하게 생각하면 그냥 토큰이 가지고 있는 특징 벡터(Feature Vector)들 사이의 거리가 가까우면 비슷하다고 할 수 있다. 하지만 저자들은 현대 트랜스포머 모델들이 '오버파라미터화(Overparameterized)' 되어 있다는 점을 날카롭게 지적한다. 예를 들어 ViT-B 모델의 경우 특징 벡터 차원이 768이나 되는데, 이는 이미지 패치 하나의 모든 픽셀 값을 다 담고도 남을 만큼 쓸데없이 거대한 공간이다. 이 말은 즉, 특징 벡터 안에는 병합을 결정하는 데 아무런 쓸모가 없는 '노이즈'들이 잔뜩 끼어 있어서 단순 거리 계산을 방해한다는 의미이다.
다행히도 트랜스포머 구조 안에는 이 문제를 아주 우아하게 해결할 수 있는 마법의 열쇠가 존재한다. 바로 QKV(Query, Key, Value) 셀프 어텐션 메커니즘이다. 어텐션 연산을 할 때 생성되는 'Key(K)' 벡터를 떠올려보자. 이 Key 벡터의 본래 목적 자체가 각 토큰이 어떤 정보를 담고 있는지 요약해서 다른 토큰들과 내적(Dot Product)하여 유사도를 구하기 위해 만들어진 녀석이다. 저자들은 바로 이 점에 착안했다. 노이즈가 낀 원본 특징 벡터를 그대로 쓰는 대신, 이미 요약이 잘 되어 있는 각 토큰의 'Key 벡터'들끼리 코사인 유사도(Cosine Similarity)를 계산해서 가장 값이 높은, 즉 가장 비슷한 토큰들을 찾아내는 방식을 채택한 것이다.
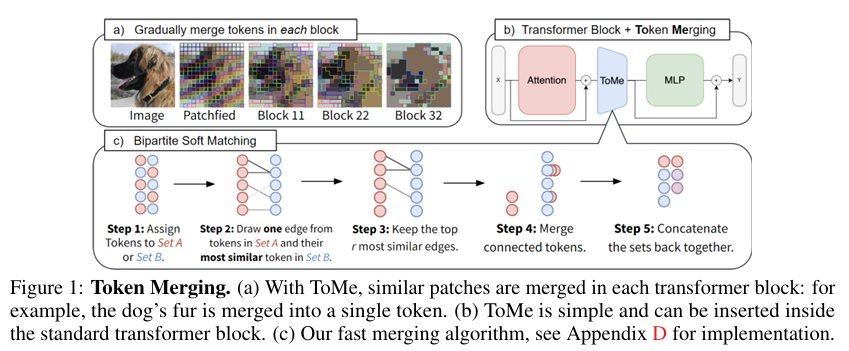
Bipartite Soft Matching
Key 벡터를 이용해 코사인 유사도를 구한다는 것까지는 정했다. 하지만 수천 개의 토큰들 사이에서 매 층마다 무려 L번이나 이 유사도를 계산해서 합칠 대상을 찾는다는 건 생각보다 엄청난 연산량을 요구한다.보통 이런 군집화(Clustering) 문제에서는 K-means이나 그래프 컷(Graph Cuts) 같은 알고리즘을 떠올리 쉽다. 하지만 저자들은 이런 전통적인 방식들을 과감히 버렸다. 왜냐하면 이런 알고리즘들은 답을 찾을 때까지 계속 반복(Iterative) 연산을 해야 해서 속도가 너무 느리고 병렬 처리도 어렵기 때문이다. 게다가 군집화는 한 그룹에 몇 개의 토큰이 묶일지 제한이 없어서, 자칫 수십 개의 토큰이 하나로 뭉쳐져 버리면 모델의 성능이 심각하게 망가질 위험이 있었다. 그래서 저자들은 반복 연산이 전혀 없고, 토큰들이 아주 '점진적으로' 합쳐질 수 있는 독창적이고 가벼운 매칭 방식을 고안해냈다.
이 매칭 알고리즘의 동작 방식은 아주 직관적이고 단순하다. 먼저 전체 토큰을 크기가 비슷한 A와 B, 두 개의 그룹으로 무작위로 반반씩 나누어 버린다. 그런 다음 A 그룹에 있는 각각의 토큰들이 B 그룹에 있는 토큰들 중 자신과 가장 비슷한(유사도가 높은) 짝꿍을 찾아서 선(Edge)를 긋는 것이다. 이렇게 짝을 다 찾고 나면, 그중에서 유사도가 가장 높은 상위 'r'개의 짝들만 서로의 특징 값을 평균 내어 하나의 토큰으로 병합하고, 합쳐지지 않은 나머지 토큰들과 다시 하나로 합치는(Concatenate) 것으로 이 과정은 끝이 난다.
이 방식이 왜 대단하냐면, A 그룹의 토큰은 B 그룹으로 딱 하나의 선만 그을 수 있는 '이분 그래프(Bipartite graph)' 형태이기 때문에 복잡한 연산 없이 곧바로 병합할 대상들을 찾아낼 수 있다. 실제로 이 방식은 무작위로 토큰을 버리는 것만큼이나 속도가 빠르고, 코드 몇 줄이면 구현할 수 있을 정도로 아주 우아한 해결책이다.

위 표의 실험 결과 (e)를 보면, 매 층마다 이 A와 B 그룹을 나누는 기준을 번갈아가며(Alternating) 바꾸어 주었을 때 성능이 가장 좋았는데, 이는 층을 통과하면서 다양한 토큰들끼리 골고루 비교될 수 있도록 만들었기 때문이다.
그런데 여기서 한 가지 문제가 발생한다. 토큰들을 병합하다 보면, 어떤 토큰은 원본 이미지의 패치 1개만 담고 있지만, 어떤 토큰은 여러 개의 패치가 합쳐져서 만들어진 '거대한 토큰'이 될 수도 있다. 즉, 토큰이 대표하는 정보의 '크기(Size)'가 달라지는 것이다.
트랜스포머의 어텐션(Attention) 메커니즘은 기본적으로 모든 토큰을 평등하게 대우하는데, 3개의 패치가 합쳐진 거대한 토큰이 평범한 1개짜리 토큰과 똑같은 영향력을 가진다면 정보의 불균형이 올 것이다. 저자들은 이를 해결하기 위해 '비례 어텐션(Proportional Attention)'이라는 기법을 도입했다. 어텐션의 소프트맥스(Softmax)를 계산할 때, 단순히 Q와 K를 곱하는 것에 그치지 않고, 각 토큰이 포함하고 있는 원본 패치의 개수(s)에 로그를 씌워(Log s) 더해준 것이다. 이렇게 하면 마치 그 키(key)가 s개만큼 복제되어 있는 것과 완벽하게 똑같은 수학적 효과를 내게 된다. 병합할 때도, 마찬가지로 이 크기(s)를 가중치로 삼아서 가중 평균(Weighted average)을 내는 것이 성능이 가장 좋았다고 위 표 (d)에서 증명하고 있다.
마지막으로 이 ToMe 기술을 모델을 '학습'시킬 때 적용하는 방법도 아주 매끄럽다.
기존의 토큰 가지치기 기법들은 미분이 불가능해서 Gumbel Softmax 같은 복잡한 수학적 트릭을 써야만 학습이 가능했다. 하지만 ToMe의 병합 과정은 그저 특징값들을 평균 내는(Average Pooling) 연산과 다를 바가 없기 때문에, 일반적인 신경망을 학습시키듯 아주 자연스럽게 역전파(Backpropagation)를 수행할 수 있다. 덕분에 학습 코드를 거의 수정하지 않고도 그냥 '드롭인(Drop-in)' 방식으로 끼워 넣어서 학습 속도를 획기적으로 끌어올릴 수 있었던 것이다.즉, 저자들은 table 1 실험을 통해 Key 벡터를 사용하고, 코사인 유사도를 쓰며, 크기에 비례하여 어텐션을 주고, 이분 매칭을 사용하는 것이 속도와 정확도를 모두 잡는 '최적의 조합'임을 논리적으로 완벽하게 증명해낸 것이다.
Experiment
ImageNet
저자들은 MAE나 SWAG 같은 기법으로 아주 잘 학습된 거대한 최첨단 모델들(ViT-L, ViT-H)을 가져와서, 추가 학습은 단 1도 시키지 않고, 그저 ToMe 모듈만 툭 얹어보았다. 모델은 이미지를 처리하는 속도(Throughput)가 정확히 2배나 빨라졌는데, 정확도 하락은 고작 0.2%에서 0.3% 수준에 머물렀다. 게다가 기존에 유행하던 토큰 가지치기(Pruning) 기법들과 동일한 조건에서 비교해 보았을 때, ToMe는 훨씬 더 높은 정확도를 유지했을 뿐만 아니라, 입력 이미지에 상관없이 항상 일정한 개수의 토큰을 줄이기 때무에 대규모 배치(Batch) 처리가 완벽하게 작동한다는 압도적인 실용성을 증명해 냈다.
Video
비디오는 수많은 이미지 프레임이 시간 순서대로 쌓여 있는 형태라 연산량이 상상을 초월하게 무업다. 저자들은 Kinetics-400이라는 거대한 비디오 데이터셋에 ToMe를 적용해 보았다. 놀랍게도 여기서 모델의 처리 속도는 2.2배나 뛰었다. 더 대단한 점은 이 ToMe를 모델의 초기 학습(Training) 과정에 직접 적용해 보았더니 전체 학습에 걸리는 시간 자체가 말 그대로 '반토막'이 났다는 것이다.
Audio
저자들은 범용성을 위해 오디오 데이터까지 끌어들였다. 소리 데이터를 이미지처럼 시각화한 Spectrogram을 ViT에 집어 넣어 분류하는 실험이었다. 오디오 스팩트로그램은 강아지나 자동차 사진과는 생김새나 정보의 분포가 완전히 다름에도 불구하고, ToMe는 여기서도 ViT-B 모델의 처리 속도를 2배 높이면서 성능 지표(mAP) 하락은 단 0.4%로 방어해 내는 기염을 토했다. 특히 오디오 실험에서는 ToMe를 적용한 상태로 아주 약간의 미세 조정(Fine-Tuning)을 거쳤을 때 성능 하락이 거의 '제로(0)'에 가깝게 복구되는 모습을 보여주었다.Conclusion
저자들은 토큰을 점진적으로 병합하여 비전 트랜스포머(ViT) 모델의 처리량을 획기적으로 늘리는 '토큰 병합(ToMe)' 기술을 성공적으로 선보였다. 이 기술의 아름다움은 데이터가 본질적으로 가지고 있는 '중복성(Redundancy)'을 아주 자연스럽게 활용한다는 데 있다. 그래서 이미지든, 비디오든, 오디오든 중복된 정보가 존재하는 어떤 형태의 데이터(Modality)에도 아무런 제약 없이 유연하게 적용할 수 있었던 것이고, 실제로 광범위한 실험을 통해 각 분야의 최고 수준 모델들과 당당히 경쟁할 수 있는 놀라운 속도와 정확도를 얻어냈다는 것을 강조한다.
'Paper Review > Model Compression' 카테고리의 다른 글