-
[Paper Review] Activation Quantization of Vision Encoders Needs Prefixing Registers (Kim et al., 2025)Paper Review/Model Compression 2026. 2. 17. 05:59
꽤나 유명한 CLIP이나 DINOv2 같은 모델들은 현대 인공지능의 시각 지능을 담당하는 핵심 엔진들이다. 하지만 이런 모델들을 자율주행 웹 에이전트나 로봇 제어 같은 실제 환경에 적용하려면, 엄청난 양의 시각 데이터를 실시간으로 처리해야 한다. 그래서 계산 비용을 줄이는 것이 매우 중요한데, 가장 효과적인 방법 중 하나가 바로 모델의 숫자를 더 작은 비트로 표현하는 '양자화'이다.
문제는 8비트(INT8) 수준의 정밀도에서도 양자화가 여전히 어렵다는 것이다. 그 주 범은 바로 Activation Outlier, 즉 모델 내부의 활성화 값 중 유난히 큰 값을 가지는 놈들이다. 이 튀는 값 하나 때문에 전체적인 숫자의 범위를 넓게 잡아야 하고, 결과적으로 나머지 평범한 값들의 정밀도가 뭉개지면서 모델의 정확도가 뚝 떨어지게 되는 것이다.
이 논문의 저자들은 이 문제를 해결하기 위해 RegCache라는 알고리즘을 제안했다. 이 방식의 가장 큰 장점은 모델을 새로 학습시킬 필요가 없는 Training-free 방식이라는 점이다. 기존 모델에 마치 플러그인 모듈처럼 툭 끼워 넣기만 하면 되는 아주 실용적인 도구인 것이다.
RegCache의 원리는 매우 흥미롭다고 생각한다. 모델에 의미는 없지만 이상치를 흡수하는 특수한 토큰(Prefix Tokens)을 주입하는 것이다. 이 토큰들이 마치 피뢰침처럼 모델 내부의 강력한 이상치들을 대신 받아내 주니까, 실제 이미지의 정보를 담은 다른 토큰들은 이상치로부터 자유로워지고 결과적으로 양자화 오류가 줄어들게 된다.
여기서 이 논문은 혁신적인 발견을 한다. 그것은 Vision 모델의 이상치가 언어 모델(LLM)과는 다르게 행동한다는 점이다. LLM에서는 문장의 맨 앞 토큰(BOS 등)이 주로 이상치를 담당하지만, Vision 모델에서는 이상치가 중간 레이어부터 서서히 나타나는 독특한 특성을 보인다.
이 관찰을 바탕으로 저자들은 두 가지 핵심 기술을 제안한다.
- Middle-layer prefixing : 이상치가 발생하는 중간 레이어부터 특수 토큰을 넣는 방식이다.
- Token deletion : 이상치를 유발하는 불필요한 토큰을 아예 삭제해 버리는 과정이다.
결론적으로 다양한 실험을 통해, 텍스트로 학습된 CLIP이나 자기지도학습으로 학습된 DINOv2 모두에서 양자화된 모델의 정확도를 일관되게 향상시킨다는 것을 입증해냈다.
Introduction
위에서 설명 했듯이 CLIPI이나 DINOv2 같은 비전 인코더들은 오늘날 자율주행이나 로봇 제어 같은 다양한 멀티모달 인공지능의 핵심 엔진으로 자리잡았다. 이런 기술들이 엣지 기기(로봇, 모바일 등)에서 실시간으로 돌아가려면 연산 비용을 줄여야 하는데, 이때 가장 유망한 기술이 바로 추가 학습이 필요 없는 PTQ(Post-Training Quantization)이다.
특히 비전 모델은 LLM처럼 단어를 하나씩 생성하는 방식(Autoregressive)이 아니라 전체 이미지를 한꺼번에 처리하기 때문에, 메모리 속도보다는 연산 자체의 속도(Compute-bound)가 병목이 되는 경우가 많다. 그래서 가중치(Weight)뿐만 아니라 활성화 값(Activation)까지 모두 낮은 비트(예: int8)로 양자화하여 연산 에너지와 시간을 아끼는 것이 매우 중요하다.
하지만 비전 모델의 활성화 값에는 Outlier(이상치), 즉 소수의 채널에서 비정상적으로 튀는 거대한 값들이 존재해 양자화가 쉽지 않다. 이 튀는 값 하나 때문에 전체 양자화 범위(Range)를 너무 넓게 잡게 되고, 결과적으로 대다수의 평범한 값들이 정밀도를 잃고 뭉개지며 성능이 급격히 떨어지게 되는 것이다.
최근 LLM 양자화 연구에서는
BOS나SEP같은 의미 없는 토큰들이 이상치를 흡수하는 'Attention Sink' 역할을 한다는 것을 발견했다. 그래서 이 토큰들을 접두사(Prefix)로 넣어주면 다른 토큰들의 활성화 수치가 안정화되어 양자화 성능이 올라가기도 한다.그럼 "비전 모델에도 이런 싱크 토큰을 넣으면 되지 않을까?"라고 생각할 수 있지만, 그것이 쉽지가 않다... 그 이유는 다음과 같다.
LLM의 경우 정해진 단어 집합이 있지만, 비전 모델은 다양한 이미지 패치를 연속적인 벡터로 만들기 때문에 어떤 패치가 '의미 없는 싱크 토큰' 역할을 할지 미리 알기 어렵다. 또한 대부분의 비전 인코더는 학습 단계부터BOS같은 명시적인 의미 없는 토큰(Register)을 가지도록 설계되지 않았다.
하지만 저자들은 여기서 아주 중요한 두 가지 실험적 발견을 하게 된다.- 점진적 발생 : 비전 모델의 이상치는 초기 레이어가 아니라 중간 레이어부터 서서히 형성된다는 점이다. 이는 모델이 이미지를 처리하면서 "어떤 부분이 의미 없는 배경인지"를 파악한 후에야 이상치가 나타나기 때문이다.
- 이미지간 유사성 : 흥미롭게도 이렇게 형성된 이상치 토큰들은 서로 다른 이미지들 사이에서도 매우 유사한 형태를 띠고 있다. 즉 특정 이미지에서 뽑은 이상치를 다른 이미지의 처리에 '범용 피뢰침'으로 쓸 수 있다는 의미이다.
이 관찰을 바탕으로 제안된 것이 바로 RegCache(Register Caching) 알고리즘이다.
- 중간 레이어 주입 : LLM 처럼 처음부터 끼워 넣는 게 아니라, 이상치가 발생하는 중간부터 마지막 레이어까지만 미리 계산된 이상치 토크(Key-Value Cache)을 주입한다.
- 토큰 삭제(Token Deletion) : 외부에서 깨끗한 피뢰침(Cache)을 넣어주는 것에 그치지 않고, 모델 내부에서 자체적으로 생겨나 이상치를 퍼뜨리는 기존의 지저분한 싱크 토큰들은 아예 삭제해 버린다.
결과적으로 RegCache는 모델의 재학습 없이도 활성화 값의 동적 범위를 좁혀주어, 기존의 어떤 양자화 기법과 결합해도 성능을 획기적으로 높여주는 강력한 '도우미' 역할을 수행하게 된다.
Related Work
대규모 트랜스포머 모델(LLM, ViT 등)에서는 특정 레이어의 활성화 값(Activation)이 다른 값들보다 비정상적으로 커지는 이상치 현상이 발견되어 왔다. 연구에 따르면, 이 현상은 주로 Self-attention 메커니즘 내의 Softmax 연산 때문에 발생한다고 한다.
- LLM :
BOS나SEP같은 특정 토큰들이 일관되게 거대한 이상치를 만들어낸다. - ViT : 비전 분야에서는 보통 아무 정보가 없는 배경 패치들이 이런 이상치 토큰이 되는 경향이 있다.
- 차이점 : 하지만 LLM과 달리 비전 모델은 이미지마다 배경이 제각각이라, 정확히 "어떤" 시각적 토큰이 이상치를 유발하는지 특정하기가 매우 어렵다.
이 논문의 저자들은 바로 이 지점에서 이상치 토큰은 중간 블록에서 발생하며, 이미지와 상관없는 유사한 특징을 공유한다.는 사실을 발견해내며 문제를 해결할 실마리를 찾았다.
정보 값은 거의 없으면서 어텐션 점수만 과도하게 빨아들이는 토큰을 어텐션 싱크라고 부른다. 비전 모델에서 이런 싱크 토큰은 어텐션 맵을 노이즈로 채워 성능을 떨어뜨리는 주범이 된다.
- 기존 방법(학습 기반) : Darcet 등은 학습 단계에서 레지스터 토큰을 추가해 어텐션을 분산시키는 방법을 제안했다.
- 최근 시도(테스트 단계) : Jiang 등은 특정 뉴런의 최대치를 테스트 시점에 0으로 초기화된 토큰에 붙여넣는 방식을 제안하기도 했다.
- RegCache의 관점 : 이 논문은 여기서 한 걸음 더 나아가, 다른 이미지에서 미리 계산된 싱크 토큰을 가져와 현재 이미지의 이상치를 흡수하는 피뢰침으로 쓰자는 아이디어를 냈다.
그동한 ViT의 추론 비용을 줄이려는 PTQ(Post-Training Quantization) 연구는 활발했다. 초기에는 레이어마다 비트 수를 다르게 할당하는 방식을 사용했으며, RepQ-ViT나 PTQ4ViT 같은 최신 기법들은 이상치의 영향을 최소화하는 정교한 양자화 스킴을 제안했다. NoisyQuant는 노이즈를 섞어 분포를 다듬기도 했다. 하지만 이런 기법들도 이상치 자체가 너무 크면 여전히 성능 하락을 면치 못했다.
RegCache는 이런 기존 양자화 알고리즘들과 대립하는 게 아니라, 그 위에 얹혀서(On-Top) 작동하는 보조 도구이다. 미리 이상치를 제압해서 동적 범위(Dynamic Range)를 확 줄여주니깐, 기존 양자화 기법들이 훨씬 더 정밀하게 작동할 수 있는 최적의 환경을 만들어주는 셈이다.
A closer look at outliers in vision encoders
이 섹션의 핵심은 비전 모델의 이상치는 LLM과 달리 중간 레이어부터 나타나지만, 일단 나타나면 모든 이미지에서 비슷한 모습을 띤다는 사실이다.
Layerwise quantization sensitivity and outliers
연구진들은 모델의 어느 부분이 양자화에 가장 취약한지(Sensitivity)를 찾아내고, 그것이 이상치(Outliers)와 어떤 관계가 있는지 밝혔다.
먼저 연구진들은 모델 전체를 한꺼번에 양자화하는 대신, 한 번에 한 레이어만 8비트(W8A8)로 양자화하고, 나머지는 그대로 둔 상태에서 정확도를 측정했다.
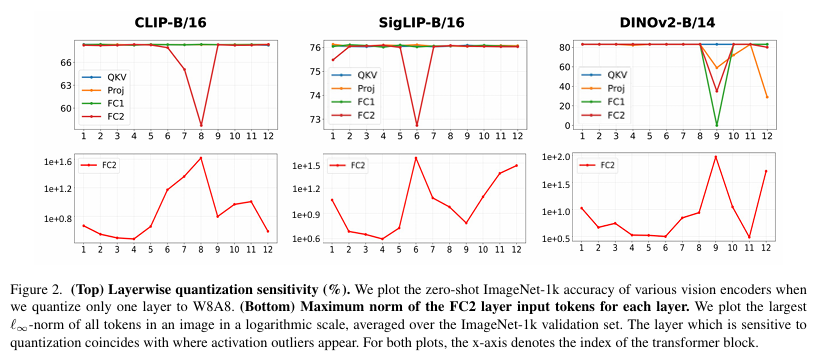
결과는 모든 레이어가 민감하지 않다는 것이다. 특정 중간 블록(Middle blocsk)의 MLP 투영 레이어(FC2)에서만 정확도가 급격히 떨어지는 현상이 발견됐다. 특히 DINOv2 모델의 경우, 이 성능 저하가 훨씬 더 날카롭고 여러 레이어에 걸쳐 나타났다.연구진들은 이 '민감한 레이어'가 어디인지 확인한 뒤, 실제 활성화 값의 크기(Norm)를 비교해 봤다. 그랬더니 소름 돕게도 정확도가 떨어지는 그 레이어가 바로 거대한 이상치(Outlier)가 발생하기 시작하는 레이어와 정확히 일치했다. 즉, 이상치가 발생해서 양자화 범위를 망가뜨리고 그 결과 성능이 떨어진다는 인과관계를 명확히 한 셈이다.
Why the middle layers?
그렇다면 왜일까? LLM의 경우 첫 레이어부터 이상치가 나오는데, 왜 Vision 모델은 중간 레이어까지 잠잠하다가 갑자기 이상치가 튀어나올까?
LLM의 경우
BOS(문장 시작)SEP(구분자)처럼 의미 없는 토큰이라고 대놓고 쓰여있는 토큰들이 있다. 모델은 이걸 보자마자 바로 Sink Token으로 써먹는다.Vision의 경우 이미지 패치들은 처음에 다 똑같은 픽셀 덩어리이다. 모델이 앞단 레이어들을 거치며 정보를 처리(Process)한 뒤에야 비로소 "아, 이 부분(배경 등)은 정보가 없으니 무의미하구나"라고 깨닫게 된다. 즉, 어떤 토큰이 쓸모없는지 파악하는 빌드업 시간이 필요하기 때문에 중간 레이어부터 이상치가 생긴다는 가설이다.
연구진들은 그래서 이 가설을 검증하기 위해 실험을 설계했다. ImageNet-9 데이터셋을 사용해서 다음 두 가지 경우를 비교했다.
- Original : 일반적인 이미지(배경 + 물체)
- Foreground-only : 배경을 싹 지워버리고(0으로 만듦) 물체만 남긴 이미지

실험 결과, Foreground-only 이미지에서는 배경이 까맣게 칠해져 있으니, 모델 입장에서는 여기는 무의미한 곳이네라고 판단하기가 쉬웠는지, 배경이 지워진 이미지에서는 이상치가 훨씬 더 앞쪽 레이어(초반)에서, 더 크게 발생했다. 반대로 배경만 남긴 이미지는 원본 이미지와 거의 똑같은 패턴을 보였다.
즉, Vision 모델의 성능 저하는 중간 레이어의 이상치 때문이며, 이 이상치가 중간에 생기는 이유는 모델이 이미지 내의 '무의미한 영역(배경)'을 식별하는 데 시간이 걸리기 때문이다.
Universality of outlier tokens
연구진들은 앞서 이상치가 중간 레이어에서 발생한다는 것을 확인 후, 이상치들의 성격을 파악하기 위해 SigLIP-B/16 모델을 가지고 실험을 진행했다.
연구진은 ImageNet-1k 검증 데이터셋에서 무작위로 64장의 이미지를 뽑았다. 그리고 각 이미지에서 양자화에 민감한 중간 레이어(FC2)의 입력값을 살펴봤다.
- 이상치 토큰(Outlier Tokens) : 각 이미지에서 값이 가장 큰($l_{\infty}-norm$이 가장 큰) 토큰들
- 일반 토큰(Normal Tokens) : 그 외의 평범한 토큰들.
위 두 토큰 들이 서로 얼마나 닮았는지, 코사인 유사도(Cosine Simiilarity)를 계산해 보았다. 즉, '강아지 이미지의 이상치'와 '자동차 이미지의 이상치'가 얼마나 비슷한지 본 것이다.
실험 결과는 명확했다.
- 일반 토큰(Normal Tokens) : 유사도가 0.26(±0.10)밖에 안됐다. 뭐 당연한 사실이다 강아지 그림의 일반 토큰(털, 눈)과 자동차 그림의 일반 토큰(바퀴, 창문)은 서로 정보가 다르니까 유사도가 낮을 수 밖에 없다.
- 이상치 토큰(Outlier Tokens) : 이상치 토큰 간의 유사도는 0.89(±0.07)로 엄청 높은 수치를 기록했다. 즉, 서로 다른 이미지에서 나온 이상치들이 사실상 거의 같은 벡터라는 것이다.
이 결과는 결국 이상치들은 입력 이미지가 무엇이든 상관없이(Independent of input image) 공통된 구성 요소를 가지고 있다는 의미이다. 즉, 이상치는 이미지 내용(강아지냐 고양이냐) 때문에 생기는 게 아니라, 모델 구조상 발생하는 범용적인 특징(Universal feature)이라는 의미이다.
이론적으로는 이상치의 엄청난 크기(magnitude)와 특정 채널에 쏠리는 위치(Location) 때문에 이런 현상이 발생한다고 한다.
결국 이상치들이 어차피 다 똑같이 생겼다면, 굳이 힘들게 매번 계산할 필요가 없다. 그냥 미리 대표적인 이상치 하나만 잘 계산해서 저장(Cache)해두고, 어떤 이미지가 들어오든 그 녀석을 피뢰침으로 써먹자는 전략이 가능해진 것이다. 이게 바로 RegCache가 Training free 이면서도 효율적인 이유이다.
Method
앞서 설명한 내용은 다음과 같다.
LLM은 초반 레이어에서 이상치가 나오지만, Visioin Encoder는 중간 레이어(예: 5~8번 블록)에서 이상치가 발생한다.
중간 레이어에서 발견된 이상치 토큰(Sink Tokens)들은 이미지와 상관없이 서로 매우 비슷하다.
이 두 가지 관찰에 "싱크 토큰을 앞에 붙여주면(Prefixing) 이상치가 완화된다."는 기존 LLM 연구 결과를 합쳐서, 저자들은 다음과 같은 새로운 가설을 세웠다.
"다른 이미지에서 가져온 중간 레이어 싱크 토큰이라도, 이를 '레지스터(Register)"처럼 사용하면 현재 이미지의 이상치를 완화할 수 있을 것이다."
즉, 이상치가 범용적(Universal)이라는 점을 이용해, 다른 이미지의 이상치를 가져와서 내 피뢰침으로 사용하겠다는 전략이다.
이 가설을 바탕으로 RegCache가 탄생했다. 핵심은 **내부에서 자연적으로 생기는(Emerging) 이상치 토큰을, 외부에서 가져온 검증된 이상치 토큰(Registers)으로 "교체(Replace)"해 버리는 것이다.

전체 과정은 크게 3단계로 이루어져 있다.
- 선별(Curating) : 수많은 참조 이미지(Reference images)들 중에서 가장 강력한 '이상치 후보(Candidate tokens)'들을 뽑아내는 과정이다.
- 캐싱(Caching) : 선별된 후보들의 Key와 Value 값을 저장해 뒀다가, 실제 모델의 "민감한 레이어(Sensitive layers)"에 주입하는 과정이다.
- Deleting : 모델 내부에서 자연 발생해서 노이즈를 유발하는 기존 싱크 토큰들을 제거하는 과정이다.
저자들은 이 알고리즘의 효율성을 특히 강조한다.
- Training Free : 모델을 재학습하거나 파라미터를 튜닝할 필요가 전혀 없다.
- Low Cost : 약간의 검증 과정(Validation)만 거치면 되기 때문에, 막대한 데이터나 계산 자원이 필요하지 않다.
- Inference Speed : 추론 단계에서 토큰을 몇 개 넣고 빼는 작업이 추가되지만, 그 비용은 무시할 수 있을 정도로 작고(Negligible), 심지어 평균적으로는 연산 비용이 감소하기도 한다.
1. Curating
먼저 의사가 환자의 아픈 부위를 찾듯, 모델에서 양자화했을 때 가장 치명적인 레이어를 찾아야 한다.
- 진단 방법 : 이미 학습된 비전 인코더의 레이어들을 하나씩 따로따로 양자화해 보는 것이다.
- 판정 기준 : 특정 레이어를 양자화했을 때, ImageNet-1k 분류 같은 대표적인 작업의 정확도가 가장 낮게 나오는 레이어를 **양자화 민감 레이어($l_q$)로 지정한다. 만약 사용할 특정 양자화 알고리즘이 있다면, 그걸 사용하고 없으면 가장 기본적인 반올림 방식(Round-to-Nearest)을 써서 테스트 한다.
민감한 레이어는 곧, 이상치가 가장 활개 치는 곳이니, 여기에 피뢰침을 설치해야 한다는 신호이다.
민감한 레이어($l_q$)를 찾았으니, 이제 그곳에 투입할 '강력한 피뢰침(레지스터)' 후보들을 뽑아야 한다. 이 논문에서는 ImageNet-1k 훈련 데이터 중 50000장을 무작위로 뽑아서 사용했다.
선별 기준은 다음과 같다.
모델에 이미지를 통과시켰을 때, 아까 찾은 민감한 레이어($l_q$) 입력단에서 $l_{\infty}$ norm(절댓값이 가장 큰 값)이 가장 큰 토큰들을 찾는다. 이 중 상위 $k$ = 100개의 토큰을 최종 후보($S$)로 선발한다. 수식으로는 다음과 같이 표현한다.
$$
S = \text{argtopk}{||z||_{\infty} \ z \in \Phi(x), \ x \in \mathcal{I}{ref}}
$$여기서 끝이 아니다. 저자들은 이상치가 폭발하기 직전인 앞단계 블록들에도 미리 피뢰침을 심어두면 더 효과적일 테니까, 각 블록에 맞는 후보 세트를 별도로 다 만들어준다. 즉, 가장 민감한 레이어뿐만 아니라, 그 앞쪽의 3개 블록까지 추가로 탐색한다.
2. Caching
Caching 단계는 전 단계에서 선발한 이상치 후보들을 정제해서 모델에 '레지스터(Register)' 형태로 주입하는 과정이다. 단순히 후보 토큰 하나를 툭 던져 넣는게 아니라, 정교한 공정을 거친다.
먼저 후보군($S$)에 있는 여러 토큰을 그대로 다 사용하지 않는다. 대신 이들의 Key-Value(KV) 캐시를 평균(Average) 내서 하나의 대표 레지스터를 만든다. 개별 이미지에서 나온 노이즈를 줄이고, 모든 이미지에 통하는 범용적인(Universal) 성질만 남기기 위해 평균을 낸다.
이제 이 '대표 레지스터'를 모델의 중간 레이어(민감한 블로고가 그 이후 블록들)에 끼워 넣어야 한다. 그런데 여기서 중요한 질문이 생긴다. "과연 몇 개나 넣어야 효과적인가?"
너무 적게 넣으면 이상치를 충분히 흡수하지 못할 것이고, 너무 많이 넣으면 모델의 연산량이 늘어나거나 원래 정보를 해칠 수 있다. 그래서 저자들은 레지스터를 몇 번 복사해서 넣을지 결정하는 파라미터 $\tau$를 최적화하는 과정을 거친다.
최적화 개수($\tau$)를 찾는 과정은 다음과 같다.
- KV 계산 : 먼저 양자화되지 않은(Unquantized) 원본 모델을 사용해서, 앞서 뽑은 후보 토큰들의 KV 캐시를 미리 계산해둔다. (이때 민감한 블록의 몇 단계 앞부터 마지막 블록까지 다 계산한다.)
- 반복 실험 : 이제 양자화된 모델에 이 KV 캐시(평균낸 것들)를 1개부터 15개까지($\tau \in {1,...,15}$) 개수를 바꿔가며 넣어본다.
- 최종 선택 : ImageNet-1k 훈련 데이터셋(Reference task)에서 분류 정확도가 가장 높게 나오는 개수 $\tau$를 최종적으로 선택한다.
참고로. 이 최적화 과정은 RTX 4090 GPU 기준으로 약 1시간 정도밖에 안걸린다. 모델 전체를 재학습하는 것에 비하면 정말 눈 깜짝할 새 끝나는 것이다.
3. Deleting
외부에서 강력한 피뢰침(레지스터)를 심어줬지만, 안심하긴 이르다. 아직 모델 내부에서 자연적으로 생겨나는 이상치들이 남아있기 때문이다.
먼저 앞서 찾았던 양자화 민감 블록의 입력단에서 수행한다. 실제 추론 중에 이미지 패치들 사이에서 스멀스멀 기어 나오는 Sink Tokens들을 제거해줘야한다.
추론 시에 테스트 이미지 $x_{\text{test}}$가 들어오면 다음과 같이 작동한다.
- 범인 색출: 민감한 레이어($l_q$)에 도달한 토큰들 중에서 $l_{\infty} norm$이 가장 큰 녀석들을 찾는다.
- 즉결 처형: 상위 $k$개의 토큰을 선정해서 모델에서 삭제해버린다.

여기서도 몇 개($k$)를 지울지 결정해야 한다. 역시 Cahcing 단계와 마찬가지로 참조 작업(Reference task)의 성능을 기준으로 최적의 개수를 찾아낸다.
결국 Caching을 통해 외부에서 검증된 깨끗한 피뢰침(레지스터)을 복사해 넣어주고, Deleting으로 내부에서 발생한 더러운 피뢰침(이상치)은 삭제해 버리는 것이다. 이렇게 하면 모델의 활성화 값 범위(Dynamic Range)가 아주 안정적으로 변해서, 양자화를 해도 성능 저하가 거의 없는 상태가 되는 것이다.
Experiment
Setup
연구진들은 이 방법론이 특정 상황에서만 통하는 게 아니라는 걸 보여주기 위해 아주 다양한 환경을 구성했다.
- CLIP, OpenCLIP, SigLIP, SigLIP2, DINOv2 등 5가지 대표적인 비전 모델을 사용했다. 텍스트와 함께 학습된 CLIP계열 모델과 이미지로만 학습된 모델 DINOv2을 모두 포함했다.
- 평가 과제는 제로샷 이미지 분류(ImageNet-1k), 이미지-텍스트 검색(MS-COCO) 또한, ImageNet 외에 Stanford Cars, Flowers-102 등 4개 다른 데이터셋에서도 테스트했다.
- 비교 대상은 PTQ4ViT, RepQ-ViT 등의 모델 구조를 고려해 양자화하는 방식과 NoisyQuant, 입력 분포를 조정(Shaping)하는 방식, 이들과 RegCache를 결합했을 때 성능이 얼마나 더 오르는지를 8비트, 6비트, 4비트 환경에서 비교했다.
Experiment Results
결과는 매우 성공적이었다. 이미지 분류(ImageNet-1k), RegCache를 적용했을 때 거의 모든 설정에서 정확도가 올랐다. 특히 기존 방법론들이 힘을 못 쓰던 4비트, 6비트 같은 저정밀도(Low-bit) 환경에서 성능 향상 폭이 훨씬 컸다.

이미지-텍스트 검색(MS-COCO), 마찬가지로 RegCache를 결합했을 때, 평균적으로 더 높은 검색 성능을 보였다.

즉, RegCache는 어떤 양자화 알고리즘과도 잘 어울리는 훌룡한 파트너라는 것이 입증된 셈이다.그렇다면 이 알고리즘이 "왜 작동할까?"
이상치 크기 감소(Reducing token norm outliers) : 아래 표를 보면, RegCache를 적용한 후 양자화 민감 레이어의 최대 토큰 크기가 확연히 줄어든 것을 볼 수 있다. 가장 큰 값이 줄어들었다는 건, 양자화해야 할 범위(Dynamic Range)가 좁아졌다는 의미이다. 덕분에 Scaling을 더 촘촘하게 할 수 있는 것이다.

접두어의 범용성(Universality of prefixes) : ImageNet 데이터로 만든 레지스터를 다른 데이터셋에 써도 되는지 확인했다. 실험적으로 봤을 때 성능이 여전히 좋았다. 이는 찾은 레지스터가 특정 데이터에 과적합(Overfit)된 게 아니라, 진짜 범용적인 이상치 제거 능력을 가졌다는 것을 의미한다.

제거(Deleting)와 주입(Caching)의 시너지 : 둘 중 하나만 하면 오히려 성능이 떨어지기도 했다. 하지만 둘을 같이 썼을 때(Synergy) 비로소 최고의 성능이 나왔다. 즉 서로 보완하는 필수 과정인 것이다.

즉, RegCache는 다양한 모델과 작업에서, 특히 어려운 저비트 환경일수록 빛을 발하며(성능 향상), 이는 실제로 이상치 크기를 줄여주고, 어떤 데이터에도 통하는 범용성을 가졌다.
Conclusion
결론적으로, RegCache는 추가 학습이 필요 없는(Training-free) 알고리즘으로, 기존의 다양한 PTQ 방법론과 결합해 성능을 높일 수 있다. 작동 원리는 양자화에 민감한 레이어의 활성화 값 이상치를 억제하여, 입력값의 동적 범위(Dynamic Range)를 좁힘으로써 양자화 오차를 줄이게 되는 것이다. 외부 이상치를 주입하는 캐싱과 내부의 이상치를 제거하는 삭제가 상호 보완적으로 작용할 때 최고의 성능을 내지만, 삭제할 토큰 수나 접두어 개수 같은 하이퍼파라미터를 모델마다 경험적으로 튜닝해야 한다는 점은 한계로 남는다.
이 논문을 통해, 무언가를 더하는 것 뿐만 아니라 불필요한 정보를 과감히 삭제하는 것 또한 성능 향상의 핵심 키가 될 수 있음을 느꼈다. 또한 어떻게 보면 "이상치(Outlier)"는 제거할 대상이 아니라, 잘 다루면 성능을 높여주는 도구가 될 수 있다는 역발상을 하게 된 것 같다.
이상치는 사실 모델이 쓸모없는 패치들에게 엄청나게 높은 Attention Score를 주기 때문에, 정말 필요악이다. 하지만 이걸 그냥 없애버리면 softmax를 통해 확률로 나올때, 다른 정보에 대한 확률이 강제로 증폭된다. 즉, 노이즈가 증폭되는 것이다. 이렇게 되면 모델이 환각(Hallucination)을 보게 만든다. 이런 문제 때문에 이상치가 참 골칫덩어리인데 해당 논문은 외부에서 검증된 깨끗한 register를 먼저 심어서 어텐션을 그쪽으로 유도한 뒤, 내부에서 멋대로 자라난 Outlier를 제거함으로써, 정보 손실 없이 양자화 범위를 안정화 시키는 것이다.
즉, 외부 레지스터는 내부 이상치와 똑같이 Outlier이지만, 이 놈이 혼자 어텐션 몰빵을 받아서 혼자 값이 커져준 덕분에, 나머지 진짜 중요한 이미지 토큰들은 값이 작고 고르게(Flat)하게 유지되어 결과적으로 중요한 정보들의 양자화 범위가 좁고 안정적으로 변하는 것이라고 이해했다.
Clipping 해버리면, 구현은 쉬우나 Softmax 분포가 깨져 노이즈가 발생할 것이고, 재학습하자니, 비용과 시간이 너무 크고, 수학적으로 펴주자니, 동적인 이상치에 대해 적용하기 까다롭기도하니 RegCache 처럼 Register 주입은 꽤나 효율적인 방법이라고 생각한다. 비용적으로나 성능적으로나 좋은 아이디어라고 생각한다.
'Paper Review > Model Compression' 카테고리의 다른 글