-
[Paper Review] Post training 4-bit quantization of convolutional networks for rapid-deployment (Banner et al., Intel, 2019)Paper Review/Model Compression 2026. 2. 18. 22:35
합성곱 신경망(CNN)은 성능은 뛰어나지만, 연산 과정에서 엄청난 메모리 대역폭과 저장 공간을 소모한다. 이를 해결하기 위해 소수점 데이터를 정수 데이터로 바꾸는 '양자화'를 사용하는데, 문제는 기존의 방식들(예: 8-bit 미만 양자화)이 성능 하락을 막기 위해 전체 데이터셋을 가지고 다시 학습(Fine-Tuning)하는 과정을 거쳐야 한다는 점이다. 하지만 실제 현장에서는 보안이나 개인 정보 문제로 전체 데이터를 사용할 수 없는 경우가 많고, 학습 자체에 들어가는 시간과 비용도 만만치 않다. 이 논문은 바로 데이터가 부족하고 다시 학습할 시간도 없는데, 어떻게 하면 4-bit 수준의 정밀한 양자화를 성공시킬 수 있을까?라는 질문에서 연구를 시작한다.
이 논문은 추가 학습 없이도 정확도를 유지하기 위해 '텐서 수준'에서 발생하는 양자화 오차를 최소화하는 세 가지 방법을 제안한다.
첫 번째는 ACIQ(Analytical Clippiing for Integer Quantization)이다. 보통 양자화를 할 때 데이터의 최솟값과 최댓값 사이를 일정한 간격으로 나누는데, 데이터가 종 모양(가우시안 분포 등)을 띠는 신경망 특성상 양 끝에 있는 아주 적은 양의 값(Outliers) 때문에 정작 중요한 중앙 데이터의 해상도가 떨어지는 문제가 발생한다. ACIQ는 수학적으로 최적의 '클리핑(Clipping)' 범위를 계산해서, 아주 일부의 극단적인 값은 포기하되 대부분의 정보가 몰려 있는 구간의 표현력을 극대화하는 방식이다.
두 번째는 채널별 비트 할당(Per-channel bit allocation)이다. 모든 채널에 똑같이 4-bit를 주는 게 아니라, 정보량이 많거나 오차가 민감한 채널에는 비트를 더 많이 주고, 덜 중요한 채널에는 적게 주는 방식이다. 이때 전체 비트 수의 평균은 4-bit를 유지하게끔 설계해서 매모리 이득은 그대로 챙기면서도 전체적인 정확도는 높일 수 있었다.
세 번째는 편향 보정(Bias-correction)이다. 가중치 값을 양자화하고 나면 원래 데이터가 가졌던 평균(Mean)이나 분산(Variance)이 미세하게 변하게 된다. 이 논문은 양자화 후에 발생하는 이 오차를 간단한 보정 상수를 이용해 다시 원래 값에 가깝게 맞춰주는 방법을 제안했다.
ACIQ: Analytical Clipping for Integer Quantization
저자들은 우리가 다룰 데이터가 어떤 놈인지부터 정의하고 시작한다.
$X$는 우리가 양자화하고 싶은 딥러닝 모델의 텐서(가중치나 활성화 값)를 의미하고, 이 값들은 아주 정밀한 실수(High precision) 상태이다. 그리고 이 데이터들은 제멋대로 퍼져 있는 게 아니라, 어떤 확률 밀도 함수 $f(x)$를 따르며 분포되어 있다고 가정한다.여기서 중요한 전제 조건이 하나 나온다. 바로 평균이 0이다. $(E(X) = \mu = 0)$라고 가정하는 부분이다. 왜 굳이 0이라고 못 박았을까? 사실 실제 데이터의 평균이 0이 아닐 수도 있다. 하지만 저자들은 "일반성을 잃지 않는다(Without loss of generality)"라고 말한다. 왜냐하면, 만약 데이터의 평균이 0이 아니더라도, 전체 데이터에서 평균만큼 뺴서 0으로 맞춘 다음 계산하고, 나중에 다시 더해주면 되기 때문이다. 이렇게 중심을 0으로 맞춰야 앞으로 나올 수식들이 대칭(Symmetric) 형태가 되어 계산이 훨씬 깔끔해지기 때문이다.
여기서 기존 방식의 문제점을 짚고 넘어가자. 이때 당시 보통은 Min-Max Quantization이라는 방식을 사용한다. 이건 텐서 안에 있는 가장 작은 값(Min)부터 가장 큰 값(Max)까지 전체 범위를 다 사용하는 방식이다. 언뜻보면 합리적이지만, 저자들은 Min-Max 방식이 최적이 아니다(Suboptimal)라고 지적한다. 왜냐하면 딥러닝 데이터는 가스 분포 등의 종 모양이라 대부분의 값이 0 근처에 모여 있는데, 아주 가끔 뜬금없이 크거나 작은 '이상치(Outliers)'가 존재하기 때문이다. 이 이상치 하나 때문에 전체 범위가 확 늘어나 버리면, 정작 중요한 0 근처의 데이터들을 표현할 비트(Bit)가 낭비되어서 해상도가 떨어지게 되기 때문이다. 그래서 저자들은 **범위를 전체 다 사용하지 말고, $[-\alpha, \alpha]$까지만 딱 잘라서(Clip) 쓰자고 제안한다.
$$
clip(x, \alpha) =
\begin{cases} x & \text{if } |x| \le \alpha
\\ \text{sign}(x) \cdot \alpha & \text{if } |x| > \alpha \end{cases}
$$
위 식의 의미는, 데이터 $x$가 우리가 정한 울타리 $[-\alpha, \alpha]$ 안에 있으면($|x| \le \alpha$) 원래 값을 그대로 사용한다. 하지만 울타리를 넘어가 버리면($|x| > \alpha$), 그냥 경계값인 $\alpha$나 $-\alpha$로 퉁쳐버리는 것이다. 여기서 $\text{sign}(x)$는 부호를 살려준다는 의미이므로, 양수 쪽으로 넘어가면 $+\alpha$, 음수 쪽으로 넘어가면 $-\alpha$가 될 것이다. 이렇게 하면 이상치 정보는 잃어버리지만(Clipping Noise), 대신 울타리 안쪽의 해상도는 촘촘하게 챙길 수 있다.
이렇게 정한 범위 안에서 데이터 한 칸의 크기(Step size, $\Delta$)는 다음과 같이 정의된다.
$$\Delta = \frac{2\alpha}{2^M}$$
우리가 $M$ 비트를 사용한다고 했으니, 표현할 수 있는 정수의 개수는 총 $2^M$개가 된다. 그리고 우리가 데이터를 담을 전체 구간의 길이는 $-\alpha$부터 $+\alpha$까지니깐 $2\alpha$가 될것이다. 그러니 한 칸의 크기 $\Delta$는 당연히 전체 길이 나누기 칸의 개수가 되는 것이다.그렇다면 위처럼 범위를 정하고, Step Size까지 설정했다면, 이렇게 했을 때 구체적으로 어떤 값으로 변환되고, 총 오차(Error)는 수학적으로 어떻게 정의될까?
먼저, 쪼개진 각 구간(Bin)을 대표하는 값이 무엇인지 정의를 한다. 인덱스 $i$는 0부터 $2^M-1$까지 존재한다. 예를 들어 4비트라면 0부터 15까지 총 16개의 구간이 있을 것이다.
각 구간의 범위는 $[-\alpha + i \cdot \Delta, \quad - \alpha + (i+1) \cdot \Delta]$이다. 간단히 말해, 시작점 $-\alpha$에서 $\Delta$만큼 $i$번 간 곳부터, $i+1$번 간 곳까지라는 뜻이다.
이 구간 안에 들어온 모든 실제 값($x$)들은 이 구간의 중앙값(Midpoint)인 $q_i$로 퉁쳐서 저장된다.(Rounding)
중앙값 $q_i$를 구하는 식을 봐보자.
$$q_i = -\alpha + (2i+1)\frac{\Delta}{2}$$
위 식은 (시작점 - $\alpha$) + ($i$칸 이동: $i \cdot \Delta$) + (반 칸 이동 $0.5 \cdot \Delta$)를 정리한 것 뿐이다. 즉, 해당 구간의 딱 정중앙 좌표를 의미한다.이제 아래 식을 봐보자. 아래 식은 원래 값 $X$와 양자화된 값 $Q(X)$ 사이의 차이의 제곱에 대한 기댓값이다. 쉽게 말해 전체 오차의 총합인 것이다. 아래 식은 데이터 구간에 따라 크게 3 덩어리로 나뉘어 있다.

첫 번째 항은 Left Tail(좌측 클리핑 오차)로 이 범위($[-\infty, -\alpha]$)에 있느느 값들은 너무 작아서, 클리핑 함수에 의해 강제로 $-\alpha$가 되어버렸다. 원래 값은 $x$인데 양자화 된 값은 $-\alpha$니깐, 오차는 $(x - (-\alpha))^2$, 즉 $(x + \alpha)^2$이 되는 것이다. 즉, 너무 작은 값들을 억지로 $-\alpha$로 끌어올렸을 때 발생하는 손실이라고 이해하면 된다.두 번째 항은 중앙 양자화 오차(Quantization Noise)이다. 범위는 유효 구간($[-\alpha, +\alpha]$)이며, 각 구간 안에서 원래 값 $x$와 그 구간의 대표값 $q_i$ 사이의 차이인 $(x-q_i)^2$를 적분한다. 이 오류는 클리핑 때문이 아닌, 해상도가 제한적이라서 생기는 반올림 오차이다.
세 번째 항은 우측 클리핑 오차이다. 이 범위($[\alpha, \infty]$)의 값들은 너무 커서 강제로 $\alpha$가 되어버렸다. 오차는 원래 값 $x$와 양자화된 값 $\alpha$의 차이인 $(x - \alpha)^2$이다. 너무 큰 값(Outlier)들을 억지로 $\alpha$로 깎아내렸을 때 발생하는 손실인 것이다.
하지만 여기서 우리가 다루는 데이터의 분포는 Gaussian 또는 Laplace 분포이다. 즉 0을 기준으로 Symmetrical 하기 때문에, 굳이 첫 번째 항과 세 번재 항을 따로 계산할 필요 없이 두 항을 같은 항으로 보고, 한쪽 계산해서 곱하기 2배를 하는 식으로 계산한다.
앞서 Error에 대해 정의했고, 그렇다면 최적의 해를 어떻게 찾아갈지 살펴보자.
먼저 아래 식은 Quantization Noise를 근사하는 과정이다.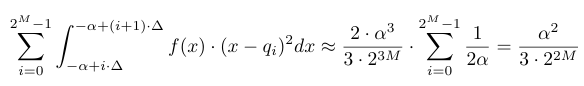
Quantization Noise
앞서 저자들은 구간 내에서 확률 밀도 함수 $f(x)$가 부드럽게 변한다고 가정하고, 이를 '조각별 선형 함수(Piece-wise linear function)'로 근사했다. 이렇게 가정하면 적분이 아주 쉬워지는데, 결과적으로 구간 내의 확률 밀도를 마치 평평한 분포(Uniform Distribution)인 $\frac{1}{2\alpha}$처럼 취급할 수 있게 된다.이 $\frac{1}{2\alpha}$를 대입해서 적분식을 풀면 $\frac{\alpha^2}{3\cdot 2^{2M}}$이 나온다. 이 수식의 의미는 "양자화 오차는 우리가 설정한 범위 $\alpha$ 의 제곱에 비례해서 커진다라는 의미로 해석할 수 있다. 즉, 클리핑 범위를 넓게 잡을수록( $\alpha$가 커질수록), 한 칸의 간격이 넓어지니 해상도가 떨어져서 오차가 팍팍 늘어난다는 의미이다.
Clipping Noise
저자들은 데이터 분포가 'Laplace Distribution'을 따른다고 가정했다. 딥러닝의 가중치나 활성화 값들은 보통 0 주변에 아주 뾰족하게 몰려 있는 형태라 라플라스 분포가 더 잘 맞는다. 라플라스 분포 식을 대입해서 꼬리 부분($\alpha ~ \infty$)을 적분하면, $b^2 \cdot e^{-\frac{a}{b}}$라는 결과가 나온다. 여기서 $b$는 분포의 퍼짐 정도를 나타내는 파라미터이다. 이 결과는 클리핑 범위를 넓힐수록($\alpha$가 커질수록), 오차가 지수적(Exponential)으로 급격히 줄어든다는 걸 의미한다. 범위를 조금만 넓혀도 잘려나가는 데이터가 확 줄어드니깐 당연한 결과라고 할 수 있다.이제 식에서 두 가지 결과를 합쳐서 '총 평균 제곱 오차(Total MSE)'를 완성한다.
$$E \approx 2 \cdot b^2 \cdot e^{-\frac{\alpha}{b}} + \frac{\alpha^2}{3 \cdot 2^{2M}}$$
앞의 항은 양쪽 꼬리에서 발생하는 클리핑 오차이고, 뒤의 항은 중앙에서 발생한 양자화 오차이다. 이 식에서 $\alpha$를 키우면 앞의 항은 줄어들지만, 뒤의 항은 커지고, 반대로 $\alpha$를 줄이면 앞의 항은 커지고 뒤의 항은 작아진다. 우리는 이 두 항의 합이 최소가 되는 딱 중간의 'Sweet Spot'을 찾아야 한다.
그 Sweet Spot은 바로 미분으로 찾는다. 총 오차 $E$를 $\alpha$로 미분해서 0이되는 지점을 찾는 것이다.
$$\frac{\partial E}{\partial \alpha} = \frac{2\alpha}{3 \cdot 2^{2M}} - 2be^{-\frac{\alpha}{b}} = 0$$
이 방정식은 $\alpha$가 지수 함수와 다항 함수 양쪽에 다 들어 있어서 손으로 깔끔하게 풀리진 않는다. 그래서 수치해석적으로(Numerically) 해를 구한다.
그 결과가 바로 이 논문의 핵심 결론인 "최적의 클리핑 값 $\alpha$"이다. 비트 수($M$)가 2,3,4일 때 각각 최적의 값은 $2.83b, 3.89b, 5.03b$로 나타났다. 이 결과는 실무적으로는 엄청난 의미를 갖는다. 왜냐하면 우리가 4비트 양자화를 하고 싶다면, 복잡한 미분 계산을 매번 할 필요 없이 딱 두 단계만 거치면 된다. 첫째, 입력 데이터 텐서 $X$의 평균 절대 편차(Mean Absolute Deviation)를 구해서 라플라스 파라미터 $b$를 추정한다($b = E(|X - E(X)|)$). 둘째, 구한 $b$에다가 그냥 5.03을 곱해준다. 그러면 이게 수학적으로 증명된 가장 완벽한 클리핑 값 $\alpha$가 되는 것이다.
Per-channel bit-allocation
기존의 방식들은 모든 채널에 똑같이 4비트를 줬다. 정보가 많든 적든, 중요하든 아니든 무조건 똑같이 나눠준 것이다. 하지만 이 논문의 저자들은 "어떤 채널은 정보가 복잡해서 4비트로는 부족하고, 어떤 채널은 단순해서 2비트만 있어도 충분하지 않을까?"라고 생각했다. 그래서 제안한 것이 가변 비트 할당이다. 어떤 채널은 5비트, 어떤 채널은 3비트를 쓰게 해주는 것이다. 단, 중요한 조건이 있는데, 전체 메모리 사용량은 변하면 안된다는 것이다. 즉, 평균을 냈을 때 여전히 4비트여야 한다는 의미이다.(Budget Contraint)
이제 이 문제를 수학적으로 정의를 해보자. 우리는 전체 오차(MSE)를 최소화하고 싶은데, 사용할 수 있는 총 구간(Bin)의 개수($B$)는 정해져 있다.
- $M_i$ : $i$번째 채널에 할당할 비트 수
- $2^{M_i}$ : $i$번째 채널이 사용하는 구간(Bin)의 개수
- $B$: 전체 채널이 사용할 수 있는 총 구간의 합
이런 '제약 조건이 있는 최적화 문제'를 풀 때 수학에서 가장 강력한 도구가 바로 라그랑주 승수법(Lagrangian Multiplier)이다.
$$\mathcal{L}(M_0, \dots, M_n, \lambda) = \sum_i \left( 2 \cdot b^2 \cdot e^{-\frac{\alpha_i}{b}} + \frac{\alpha_i^2}{3 \cdot 2^{2M_i}} \right) + \lambda \left( \sum_i 2^{M_i} - B \right)$$이 식을 뜯어보면,
- 앞부분($\sum$) : 우리가 ACIQ에서 구했던 각 채널의 오차 합이다. 이걸 최소화하는 것이 목표이다.
- 뒷부분($\lambda$) : 제약 조건이다. 우리가 쓴 총 구간($\sum 2^{M_i}$)이 $B$와 같아야 한다는 조건을 강제하는 것이다.
이제 이 비용 함수 $\mathcal{L}$이 최소가 되는 지점을 찾기 위해, 각 채널의 비트 수 $M_i$에 대해 편미준을 해서 0이 되는 지점을 찾아야 한다.
$$\frac{\partial \mathcal{L}}{\partial M_i} = -\frac{2 \ln 2 \cdot \alpha_i^2}{3 \cdot 2^{2M_i}} + \lambda \cdot 2^{M_i} = 0$$위 식을 보면, 왼쪽 항은 비트 $M_i$를 늘렸을 때 줄어드는 오차의 양을 의미하며 오른쪽 항은 비트 $M_i$를 늘렸을 때 늘어나는 비용 즉, 비트를 하나 더 써서 얻는 이득과 비용이 같아지는 지점에서 최적의 비트 수가 결정된다는 경제학적 원리와 동일하다.
물론, 제약 조건도 만족해야 하므로 $lambda$에 대해서도 미분해서 0이 되어야한다.
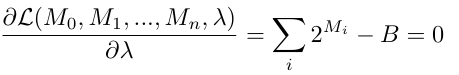
위 식 2개를 연립하여 풀면, 아래 식이 나온다.
$$2^{M_i} = \frac{\alpha_i^{2/3}}{\sum_j \alpha_j^{2/3}} \cdot B$$- $2^{M_i}$ : $i$번째 채널에 할당해야 할 구간의 개수
- $\alpha^\frac{2}{3}_i$ : 그 채널 범위($\alpha_i$)의 2/3 제곱에 비례
- $B$ : 전체 예산
결론적으로 데이터의 범위($\alpha$)가 넓은 채널일수록 더 많은 비트를 할당받는다는 것이다. 그런데 그냥 비례하는 게 아니라, 정확히 2/3승에 비례해서 나눠 갖는 게 수학적으로 가장 오차가 적다는 것이 증명된 것이다.
마지막으로 우리가 필요한 건 '비트 수(정수)'니깐, 양변에 로그($log_2$)를 취하고 반올림을 하면 최종적으로 우리가 실무에서 쓸 식이 완성된다.
$$M_i = \text{round} \left( \log_2 \left( \frac{\alpha_i^{2/3}}{\sum \alpha^{2/3}} \cdot B \right) \right)$$
즉 요약하자면 "모든 채널에 똑같이 비트를 주지 말고, 범위($\alpha$)가 큰 채널에는 더 많은 비트를 줘라. 단, 그 비율은 $\alpha^{2/3}$을 따라야 한다."는 것이다.
아래 그림을 보면, 합성 데이터 실험에서도 이 수식대로 비트를 배분했을 때 오차가 가장 작았다는 것을 확인할 수 있다. 실제로 이 방법을 적용하면 메모리 사용량은 동일한데, 정확도는 훨씬 높아지게 되는 것이다.

Bias Correction
앞서 ACIQ로 '어떻게 자를지'정하고, Bit-allocation으로 '누구에게 더 줄지' 정했다. 그런데 막상 양자화를 하고 나니 데이터의 통계적 특성 자체가 틀어지는 문제가 발생한다는 것을 저자들은 발견했다.
우리가 실수(Float)인 가중치 $W_c$를 정수(Integer)인 $W^q_c$로 변환(Quantization)하면, 필연적으로 값들이 반올림되거나 버려지면서 오차가 생길 것이다. 그런데 저자들은 이 오차가 무작위로 생기는 것이 아니라, 구조적인 편향(Inherent Bias)을 만든다는 사실을 관찰했다.
수식으로 보면 아주 명확하다.
$E(W_c) \neq E(W^q_c)$ : 평균의 이동이다. 원래 가중치의 평균과 양자화된 가중치의 평균이 달라져 버린다. 즉, 중심이 이동했다는 의미이다.$||W_c - E(W_c)||_2 \neq ||W^q_c - E(W^q_c)||_2$ : 평균을 뺀 값들의 L2 Norm이 달라졌다. 즉, 데이터가 퍼져 있는 정도(분산)가 원래보다 쪼드라들거나 늘어났다는 의미이다.
이걸 그대로 두면 모델은 내가 알던 분포가 아닌데?라며 헷갈려 하게 되고, 결국 성능 저하로 이어질 것이다.
그래서 저자들은 틀어진 만큼 다시 더해주고 곱해주자는 아주 단순하고 강력한 해결책을 내놓았다. 이를 위해 각 채널($c$)마다 두 가지 보정 상수를 계산한다.
평균 보정 상수 $\mu_c$(Shift Correction)
먼저, 틀어진 평균을 되돌리기 위한 값이다.
$$\mu_c = E(W_c) - E(W^q_c)$$
(원래 평균) - (양자화된 평균)으로 만약 양자화된 평균이 원래 보다 작아졌다면, $\mu_c$는 양수가 되어 부족한 만큼 채워주고, 커졌다면 음수가 되어 깎아내릴 것이다.분산 보정 상수 $\xi_c$ (Scale Correction)
다음은, 틀어진 분포의 크기를 되돌리기 위한 비율이다.
$$\xi_c = \frac{||W_c - E(W_c)||_2}{||W^q_c - E(W^q_c)||_2}$$
(원래 데이터의 퍼짐 정도) / (양자화된 데이터의 퍼짐 정도)로 이 비율을 곱해주면 쪼그라든 분포는 다시 펴주고, 너무 퍼진 분포는 모아줄 수 있다.이제 구한 상수들을 이용해서 양자화된 가중치 $W^q_c$를 보정해보자.
먼저 $w + \mu_c$를 통해 틀어진 중심(평균)을 원상 복구 시켜준다. 그리고 $\xi_c (\dots)$로 틀어진 크기(분산)를 원상 복구 시킨다.$$w \leftarrow \xi_c (w + \mu_c), \quad \forall w \in W^q_c$$
이렇게 하면 양자화된 값들이 통계적으로 원래의 FP32 가중치와 거의 흡사한 분포를 가지게 된다.
여기서 Folding 기법을 적용하여 추론 할 때마다 덧셈과 곱셈을 하는 비용을 0으로 만들어준다. 저자들은 $\mu_c$와 $\xi_c$를 기존에 존재하는 Scale과 Offset 변수에 미리 녹여버려 수학적으로 미리 계산해서 상수항에 합쳐버리면, 실제 추론 시에는 추가적인 연산 없이도 보정된 효과를 누릴 수 있게 된다.Combining our quantization methods
위에서 언급한 세 가지 강력한 무기들(ACIQ, Bit-Allocation, Bias-Correction)을 실제로 어떻게 조립해서 사용할지 확인해보자.
먼저 저자들은 가중치(Weights)와 활성화(Activations)에 대해 서로 다른 전략을 취했다.
첫째, 채널별 비트 할당(Per-channel bit allocation)은 둘 다 적용했다. 가중치든 활성화든, 채널마다 정보량이 다른건 매한가지이므로, 둘 다 중요한 곳에 비트를 더 주고, 덜 중요한 곳은 뺏는 전략이 유효하다고 보는 것이다.
둘째, ACIQ(클리핑)은 Activations에만 적용했다.
저자들은 실험 결과 가중치(Weights)를 클리핑하는 건 별로 이득이 없다는 것을 발견했다. 가중치는 학습이 끝나고 나면 고정된 값들이라 분포가 비교적 안정적이다. 그래서 굳이 가중치를 잘라내서(Clipping)얻는 이득보다 손실이 더 크커나 비슷하다고 판단하고, ACIQ는 활성화 텐서에만 적용하기로 한다. 활성화 값은 입력 데이터에 따라 튀는 값(Outlier)이 많이 나오므로 클리핑 효과가 아주 좋다.셋쨰, Bias-Correction은 Weights에만 적용한다.
사실 이론적으로는 활성화 값에도 편향 보정을 할 수 있다. 하지만 여기엔 치명적인 현실적 문제가 있는데, 가중치의 편향은 모델을 배포하기 전에(Offline) 미리 계산해서 수정해 놓으면 끝이지만, 활성화 값의 편향은 입력 이미지가 들어올 때마다 바뀐다. 즉, 통계를 내리면 입렉 데이터를 잔뜩 넣고 돌려봐야 하는데, 우리는 지금 '데이터가 없는(post-training)' 상황을 가정하고 있으므로, 안된다. 실행 중에 하면 되지 않나? 라고 하지만, 계산 비용이 너무 많이 들어서 배보다 배꼽이 커지는 격이다. 그래서 저자들은 과감하게 활성화에 대한 편향 보정은 포기하고, 가중치에 대해서만 적용하기로 결정한다.아래 이미지를 보면, 이 방법들이 서로 상호 보완적으로 작용해서 성능을 끌어올리는 것을 확인할 수 있다.

Experiment & Results
먼저 저자들은 6가지 대표적인 ImageNet, CNN을 가지고 실험을 진행했다. 이때 당시 가장 널리 쓰이던 방식들을 Baseliine으로 설정하고 비교했다.
여기서 먼저 2가지 핵심 설정이 들어간다.
- 채널별 양자화(Per-Channel Quantization) : 가중치나 활성화 값은 분포가 천차만별이다. 그래서 채널마다 별도의 스케일 값을 두는 것이 정확도 유지에 필수적이다.
- Fused ReLU : 보통 Conv 뒤에는 활성화 함수 ReLU가 바로 붙는다. ReLU는 음수 값을 전부 0으로 만들어 버리는데, 그렇다면 굳이 음수 구간까지 양자화 범위를 잡을 필요가 있을까? 전혀 그렇지 않다. 어피 0이될 애들이기 때문이다. 그러므로 양수 구간 $[0, \alpha]$만 잘게 쪼게서 간격을 촘촘히 하니 오차가 확 줄어들게 될 수 있는 것이다.
실험 결과는 다음과 같다.

8W4A
- Baseline: Min-Max
- ACIQ : 최적의 클리핑
- Bit-Allocation : 채널별로 비트 할당
결론적으로, 각각 따로 사용해도 성능이 오르지만, ACIQ와 Bit-Allocation을 같이 썻을 때 성능이 가장 좋았다.
4W8A
가중치가 찌그러지면서 생긴 평균과 분산의 변화를 Bias-Correction이 잡아주니 정확도가 확 뛰었다.4W4A
결과적으로 원래 FP32 모델과 비교해서 몇 퍼센트 차이밖에 안 나는 수준까지 정확도를 방어한다.Conclusion
그동안 4비트 이하의 양자화는 가능 했지만, Retraining/Fine-tuning이 필수적이였다. 하지만 현실 세계(industry)에서는 쉽지가 않다. 데이터를 보안상 받지 못하는 경우나, 데이터가 너무 방대해서 다시 학습시킬 엄두가 안나는 경우가 많기 때문이다. 그래서 이 논문의 방법을 사용하면, Data-Free, PTQ방식으로 4비트까지 배포 가능하다는 것이 매우 큰 이점이지 않나 싶다.
정확도 손실은 약간 있지만, 재학습 없이도 이 정도 성능을 낸다는 것은 매우 큰 혁신이지 않나 싶다.
'Paper Review > Model Compression' 카테고리의 다른 글