-
[Paper Review] 3D Gaussian Splatting for Real-Time Radiance Field RenderingPaper Review/3D Vision 2026. 3. 30. 12:40
3D 장면을 컴퓨터로 표현하는 방식은 크게 2가지의 흐름이 존재했다.
- Explicit (Meshes & Points) : 점(Points)이나 삼각형 메쉬(Meshes)를 사용하여 3D 공간을 정의한다. 이 방식은 GPU의 레지스터화(Rasterization) 파이프라인에 최적화되어 있어 매우 빠르다는 장점이 있다.
- Continuous (Neural Radiance Fields, NeRF) : 공간을 연속적인 함수(MLP)로 정의하며, 특정 좌표를 입력하면 그 지점의 밀도와 색상을 반환한다. 최적화 과정에서 매우 정교한 품질을 보여주지만, 렌더링을 위해 광선을 따라 수많은 지점을 샘플링(Stochastic smapling)해야 하므로 연산 비용이 크고 노이즈가 발생할 수 있다.
그렇다면 3D Gaussian Splatting이란 무엇일까?
한마디로 정의하자면, "공간을 수백만 개의 부드럽고 미분 가능한 3D 타원체(Gaussians)로 채워 장면을 표현하는 기술"이다. 이 3D Gaussian Splatting(3DGS)는 위 두 가지 3D 표현 방식의 장점을 결합한 접근법이다.
장면을 수백만 개 미분 가능한 3D Gaussians들로 구성하며, 이를 통해 NeRF의 고품질 최적화 능력과 실시간 렌더링 속도를 동시에 잡아버린다.
3D Gaussian Splatting Work Flow
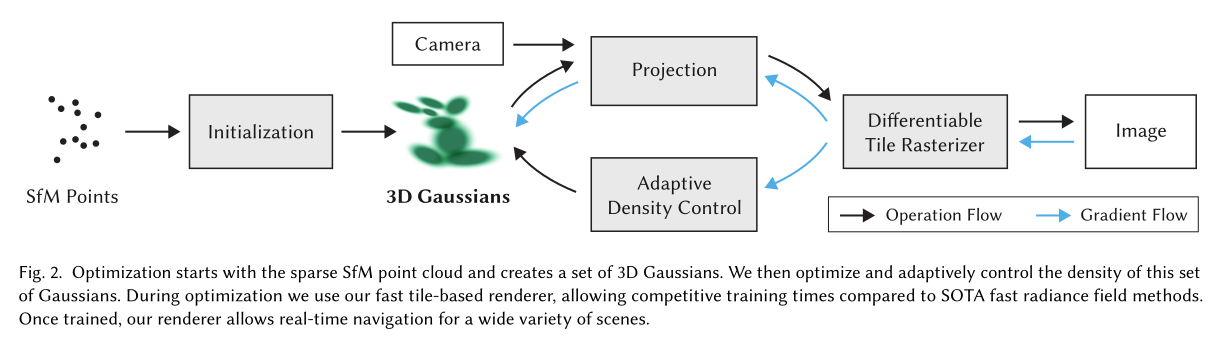
논문 Overview 섹션에서는 입력 데이터로부터 최종 렌더링까지의 과정을 네 가지 핵심 단계로 요약하고 있다.
1. 입력 및 초기화 (Input & Initialization)
- 데이터 소스 : 정적인 장면을 찍은 여러 장의 이미지와 SfM(Structure-from-Motion)으로 계산된 카메라 파라미터를 입력으로 받는다.
- 포인트 클라우드 활용 : SfM의 부산물로 생성되는 희소한(Sparse) 포인트 클라우드를 3D 가우시안의 초기 위치로 사용한다.(0에서 시작하는 것이 아니라, 대략적인 형태가 잡힌 포인트에서 시작하기 때문에 학습 수렴 속도가 훨씬 빠르다.)
2. 장면의 표현 (Representation)
장면은 수많은 3D 가우시안으로 정의되며, 각 가우시안은 다음 속성을 가진다.- 위치(Position, $\mu$): 중심점 좌표
- 공분산(Covariance, $\Sigma$) : 가우시안의 크기와 모양(타원체)
- 불투명도(Opacity, $\alpha$) : 빛을 얼마나 통과시키는지 결정
- 색상(Color, SH coefficients) : 시점(View)에 따른 색 변화를 표현하기 위해 구면 조화 함수(Spherical Harmonics, SH)를 사용한다.
여기서 SH(Spherical Harmonics)를 사용하는 이유는, 물체의 색은 보는 각도에 따라 달라질 수 있기 때문이다.(예: 광택) SH 계수를 최적화하면 단순한 색이 아니라 시점 의존적인 광휘(Radiance)를 표현할 수 있게 되기 때문이다.
3. 알고리즘: 최적화와 밀도 제어 (Optimization & Density Control)
알고리즘은 다음 두 과정을 반복(Interleaved)하며 진행된다.- 파라미터 최적화 : 가우시안의 위치, 공분산, $\alpha$, SH 계수를 업데이트한다.
- 적응형 밀도 제어 : 가우시안이 부족한 곳에 더 만들고, 불필요한 곳에선 제거하여 장면을 정교하게 다듬는다.
여기서 비등방성(Anistropic)의 이점이 발생하는데, 가우시안이 럭비공처럼 길쭉해질 수 있기 때문에, 매우 얇은 구조물도 적은 수의 가우시안으로 효율적으로 표현이 가능하다.
4. 핵심 렌더러: 타일 기반 래스터라이저 (Tile-based Rasterizer)
해당 파트가 '실시간성'을 책임진다.- 타일 기반 : 화면을 타일 단위로 나누어 병렬 처리한다.
- 빠른 정렬(Fast Sorting) : 가시성(Visibility) 순서대로 가우시안을 정렬하여 $\alpha$-blending을 수행한다.
- 제한 없는 그래디언트 : 이전 기술들과 달리, 그래디언트를 받을 수 있는 가우시안의 개수에 하드웨어적 제한을 두지 않아 훨씬 정교한 학습이 가능하다.
Differntiable 3D Gaussian Splatting
그렇다면 왜 3D 가우시안인가?
우리가 3D 세상을 컴퓨터로 그릴 때 가장 먼저 부딪히는 벽은 '표면의 방향'을 정의하는 것이다. 기존의 포인트 기반 방식들은 각 점을 아주 작은 원반(Planar circle)으로 생각했고, 이를 위해 각 점이 어디를 향하는지 알려주는 '법선 벡터(Normal)'을 필요로 했다.하지만, 처음 얻은 데이터(SfM 포인트)는 너무 듬성듬성해서 법선 벡터를 정확히 계산하기가 거의 불가능 했다. 억지로 계산하더라도 그 결과가 너무 Noisy해서 학습을 방해하게 되기 때문이다. 그래서 이 논문의 저자들은 법선 벡터가 필요 없는 3D 타원체(Gaussian)을 사용하자고 주장한다. 가우시안은 부드러운 볼륨을 가지기 때문에 뾰족한 방향 정보가 없어도 공간을 아주 훌륭하게 채울 수 있다.
먼저 3D 가우시안의 정의부터 봐보자.
$$G(x) = e^{-\frac{1}{2}(x-\mu)^T \Sigma^{-1} (x-\mu)}$$
여기서,
- $\mu$ (Mean) : 가우시안의 중심이다. 3D 공간의 특정 위치를 나타낸다.
- $\Sigma$ (Covariance) : 타원체의 모양과 크기를 결정하는 핵심 행렬이다.
이 수식을 중심 $\mu$에서 멀어질수록 값이 부드럽게 작아지는 '구름' 같은 존재를 정의한다. 여기에 투명도($\alpha$)를 곱해주면, 비로소 렌더링에 사용할 수 있는 재료가 완성된다.
이제 3D Cloud를 우리 눈(카메라)에 보이는 2D 이미지로 옮겨야 한다. 이 과정을 투영(Projection)이라고 부르는데, 공분산 행렬 $\Sigma$가 화면 위에서 어떻게 변하는지가 관건이다.
$$\Sigma' = JW \Sigma W^T J^T$$- $W$ (Viewing transformation) : 카메라가 세상을 바라보는 시점(회전과 위치)을 반영한다.
- $J$ (Jacobian) : 원근 투영이라는 복잡한 계산을 다루기 쉽게 선형적으로 살짝 비튼(Affine approximation) 자코비안 행렬이다.
이 수식을 거치면 3D 타원체는 우리 화면에 딱 맞는 2D 타원체($\Sigma'$)로 변한다. 여기서 흥미로운 점은 이 행렬의 3행 3열을 그냥 무시해버리면, 마치 평면 원반을 투영했을 때와 똑같은 구조의 $2\times 2$ 분산 행렬을 얻게 된다는 점이다.
이제 경사 하강법(Graident Descent)으로 $\Sigma$를 학습해야한다. 그런데 $\Sigma$는 수학적으로 '양의 준정부호(Positive Semi-definite, PSD)' 행렬이어야만 물리적인 타원체의 의미를 가진다.
그냥 raw 행렬을 학습시키면, 업데이트 과정에서 이 PSD 조건이 깨져서 타원체가 찌그러지거나 폭발해버릴 위험이 존재한다. 그래서 저자들은 $\Sigma$를 직접 건드리는 대신, 이를 구성 성분으로 쪼개서 학습하는 방식을 택한다.
$$\Sigma = RSS^T R^T$$- $S$ (Scaling) : 타원체의 축 방향 크기를 조절하는 스케일링 벡터 $s$를 대각 행렬로 만든 것이다.
- $R$ (Rotation) : 타원체의 회전을 결정하며, 이는 Quaternion $q$로 표현된다.
이 방식은 어떤 $s$와 $q$가 들어와도(Unconstrained) 위 수식을 통과하면서 항상 유효한 PSD 행렬을 만들어낸다. 덕분에 복잡한 제약 조건 없이도 안정적으로 모양을 다듬어나갈 수 있게 되었다.
Optimization & Density Control
현재 목표는 단순히 가우시안을 배치하는 것이 아니라, 임의의 시점에서도 실물 같은 영상을 만들어내는 고밀도의 3D 가우시안 집합을 만드는 것이다. 이를 위해 위치($p$), 투명도($\alpha$), 공분산($\Sigma$), 그리고 각도에 따른 색상을 결정하는 SH 계수($c$)를 동시에 최적화한다.
이 과정은 마치 조각가가 거친 돌덩이에서 시작해 세밀한 조걱상을 만들어가는 과정과 빗스하다. 파라미터를 미세하게 조정하는 최적화 단계와, 가우시안의 개수를 늘리거나 줄이는 밀도 제어 단계가 서로 맞물리며 진행된다.
1. Optimization
최적화의 기본 원리는 간단하다. 현재의 가우시안들을 렌더링해서 이미지를 만들고, 이를 실제 촬영된 원본 이미지와 비교하는 과정을 반복하는 것이다.
기하학적 오류의 수정
3D 공간을 2D로 투영할 때 발생하는 모호함 때문에 가우시안이 엉뚱한 곳에 배치될 수 있다. 그래서 최적화 알고리즘은 잘못된 위치의 가우시안을 이동시키거나, 파괴하거나, 혹시 새로운 곳에 생성할 수 있는 유연함을 갖춰야 한다. 특히 넓고 단조로운 구역은 커다란 비등방성(Anisotropic) 가우시안 몇 개만으로도 효율적으로 채울 수 있는데, 이는 데이터의 컴팩트함(Compactness)을 결정하는 핵심 요소가 된다.수치적 안정성을 위한 장치들
논문에서는 학습의 안정성을 위해 다음과 같은 장치들을 사용한다.- Sigmoid 활성화 함수 : 투명도($\alpha$)를 $[0, 1)$ 범위로 제한하여 부드러운 그래디언트를 얻는다.
- Exponential 활성화 함수 : 공분산의 크기(Scale)가 항상 양수가 되도록 강제한다.
- 초기값 설정 : 초기 공분산은 주변에서 가장 가까운 세 점까지의 평균 거리를 반지름으로 하는 구형(Isotropic) 가우시안으로 시작한다. 이는 초기에 가우시안들이 서로 적절히 겹치게 하여 빈틈없는 학습을 돕는다.
손실 함수(Loss Function)
하지만 단순 픽셀 값의 차이($\mathcal{L}_1$)만 줄인다고 해서 사람이 보기에 좋은 이미지가 나오지는 않는다. 그래서 논문은 시각적 유사도를 측정하는 D-SSIM을 결합한 복합 손실 함수를 제안한다.
여기서 $\lambda = 0.2$를 사용하여 두 지표의 균형을 맞춘다. $\mathcal{L}_1$은 전반적인 색상의 일치도를, D-SSIM은 구조적인 디테일과 선명도를 잡아내는 역할을 한다.
2. Adaptive Control of Gaussians
처음 SfM(Structure-from-Motion)에서 얻은 포인트들은 매우 희소하다. 이 듬성듬성한 포인트들로만 장면을 표현하기엔 역부족이란 의미이다. 그래서 시스템은 학습 과정 중에 가우시안의 숫자와 밀도를 스스로 조절하며 장면을 더 촘촘하고 정확하게 채워 나간다.
언제 움직일 것인가? --> 그래디언트 신호
가우시안을 더 만들지 말지 결정하는 가장 중요한 지표는 뷰-공간 위치 그래디언트(View-space positional gradients)이다.쉽게 말해, 최적화 단계에서 특정 지역의 가우시안들을 자꾸 옮기려고 시도한다면($\nabla_{pos}$)가 높다면), 그 지역이 아직 제대로 복원되지 않았다는 의미이다. 논문은 이 그래디언트의 평균 크기가 임계값($\tau_{pos} = 0.0002$)을 넘어서는 가우시안들을 '변화가 필요한 후보'로 낙점한다.
Clone and Split
그래디언트 신호를 받은 가우시안은 자신의 '크기'에 따라 두 가지 운명 중 하나를 맞이하게 된다.- 가우시안이 작을 때 --> 복제(Clone) : 기하학적 특징이 부족한 '미복원(Under-reconstruction)' 지역이다. 이때는 기존의 가우시안과 똑같은 크기의 복사본을 하나 더 만들고, 이를 그래디언트 방향으로 살짝 이동시킨다. 결과적으로 시스템의 전체 부피와 개수가 모두 늘어나며 빈 공간을 채우게 된다.
- 가우시안이 클 때 --> 분할(Split) : 하나의 커다란 가우시안이 너무 넓은 범위를 뭉뚱그려 표현하고 있는 '과복원(Over-reconstruction)'지역이다. 이때는 이 거대한 가우시안을 두 개의 작은 가우시안으로 쪼갠다. 크기(Scale)를 $\phi = 1.6$ 비율로 줄이고, 원래 가우시안의 분포를 확률 밀도 함수(PDF)로 삼아 새로운 위치를 샘플링한다. 전체 부피는 유지하면서 개수만 늘려 디테일을 살리는 전략인 것이다.

투명도와 크기 기반 Kill
하지만 무한정 늘리기만 하면 메모리가 폭발할 것이다. 그래서 아래와 같은 방법을 사용한다.- 투명한 녀석들 제거 : 불투명도($\alpha$)가 임계값($\epsilon_\alpha$)보다 낮은 가우시안은 렌더링에 기여하지 않으므로 과감히 삭제한다.
- 가짜들(Floaters) 소탕 : 카메라 바로 앞에 나타나 화면을 가리는 가짜 가우시안들을 막기 위해, 매 3000번의 반복마다 모든 가우시안의 $\alpha$ 값을 강제로 0에 가깝게 초기화한다. 정말 필요한 가우시안들만 다시 $\alpha$를 높여 살아남게 만드는 일종의 '생존 시험'이다.
- 거대 가우시안 제거 : 월드 공간에서 너무 크거나 화면에서 너무 넓은 면적을 차지하는 가우시안들도 주기적으로 제거하여 효율성을 유지한다.
Fast Differentiable Rasterizer
래스터라이저의 설계 목표는 다음과 같다.
전체적인 렌더링과 정렬 속도를 극단적으로 높이고, 이방성 스플랫(Anisotropic splats)에 대한 미분 가능한 $\alpha$-blending을 지원하며, 그래디언트 업데이트를 받는 스플랫 수에 제한을 두지 않는 것이다.Tile-based approach
기존의 포인트 기반 방식들은 픽셀 하나하나마다 겹치는 점들을 정렬하느라 엄청난 연산 비용을 지불했다. 3DGS는 이를 해결하기 위해 화면 전체를 16x16 타일로 나누고, 타일 단위로 가우시안을 미리 정렬(Pre-sort)하는 소프트웨어 래스터라이징 방식을 도입했다.Rendering Pipline: Pre-sort
렌더링 엔진은 크게 다음과 같은 단계를 거쳐 작동한다.1. 컬링(Culling) 및 선별 : 3D 가우시안 중 시야(View Frustm)에 들어오는 것들만 남긴다. 특히, 투영 계산이 불안정해질 수 있는 극단적인 위치의 가우시안들은 보호 대역(Guard band)을 통해 미리 제거한다.
2. 인스턴스화 및 키 할당 : 각 가우시안이 겹치는 타일의 수만큼 복제본(Instance)을 만들고, 각 인스턴스에 [타일 ID + 뷰 공간 깊이(Depth)]를 조합한 64비트 키를 부여한다.
3. GPU Radix 정렬 : 이 키들을 바탕으로 GPU에 최적화된 단일 Radix 정렬을 수행한다. 이를 통해 모든 타일 내의 가우시안들이 깊이 순서대로 정렬된다.
Forward Pass
정렬된 가우시안 리스트가 준비되면 본격적인 그리기가 시작된다.- 타일별 스레드 블록 : 각 타일마다 하나의 GPU 스레드 블록을 할당한다.
- 공유 메모리 활용 : 블록 내 스레드들이 협력하여 가우시안 데이터를 공유 메모리에 패킷 단위로 로드하여 데이터 로딩 효율을 극대화한다.
- 조기 종료(Early Exit) : 앞에서부터 순서대로 $\alpha$-blending을 진행하다가, 특정 픽셀의 투명도가 포화($\alpha \approx 1$)이 되면 해당 스레드는 연산을 멈춘다. 타일 내 모든 픽셀이 포화되면 타일 전체 연산을 종료하여 불필요한 연산을 막는다.
Backward pass
학습을 위해서는 렌더링 과정을 거꾸로 되짚어 그래디언트를 전달해야 한다.- 메모리 절약 전략 : 픽셀마다 블렌딩된 수많은 점의 리스트를 모두 메모리에 저장하려면 엄청난 용량이 필요하다. 3DGS는 이를 피하기 위해, 역방향 패스에서 타일 리스트를 다시 한번 순회(Re-traverse)하는 방식을 택했다.
- Back-to-front : 그래디언트 계산을 위해 리스트를 뒤에서부터 앞으로 훑는다.
- 중간 투명도 복구 : 모든 중간 단계의 투명도를 저장하는 대신, 최종 누적 투명도만 저장해 두었다가 역방향 순회 시 이를 각 점의 $\alpha$로 나누어 필요한 계수들을 복구해낸다.
Implementation Results and Evaluation
1. Implementation
이 논문의 구현체는 Python과 PyTorch 프레임워크를 기반으로 한다. 하지만 모든 연산을 파이썬으로 하면 실시간 성능을 낼 수 없다. 그러므로 다음과 같은 프레임워크를 추가로 사용한다.
- Custom CUDA Kernel : 렌더링의 핵심인 래스터화(Rasterization) 루틴은 직접 CUDA로 작성되었다. 이는 기존 연구를 확장한 형태이다.
- 고속 정렬 : 수백만 개의 가우시안을 순식간에 정렬하기 위해 NVIDIA의 CUB 라이브러리에 포함된 고속 Radix Sort 루틴을 사용한다.
- 인터랙티브 뷰어 : 학습된 결과를 실시간으로 확인하기 위해 오픈소스인 SIBR을 사용하여 전용 뷰어를 구축했다.
최적화 초기 단계에서는 가우시안들이 제 자리를 잡지 못해 매우 불안정하다. 이를 해결하기 위해 저자들은 'Warm-up' 전략을 사용한다.
- 해상도 조절: 처음에는 원래 이미지보다 4배 작은 해상도에서 최적화를 시작한다.
- 단계적 업샘플링 : 250번과 500번의 반복(Iteration)을 거치며 점진적으로 해상도를 높여 최종 해상도에 도달하게 된다.
- 작은 해상도에서는 전반적인 구조를 빠르게 잡고, 해상도를 높이면서 세부적인 디테일을 다듬기 위함이다. 이는 딥러닝에서 흔히 쓰이는 'Image Pyramid' 전략과 유사하다.
SH(Spherical Harmonics)는 시점에 따른 색상 변화를 표현하지만, 데이터가 부족한 경우 엉뚱한 값을 학습할 위험이 존재한다.
장면의 구석진 곳이나 한쪽 방향에서만 찍은 영상의 경우, 각도에 따른 색상 정보가 부족하여 기본 색상(Diffuse Color)조차 틀리게 계산될 수 있다.
이를 해결하기 위해,
처음에는 가장 기본이 되는 0차 SH 계수(평균 색상)만 학습한다. 이후 매 1000번의 반복마다 SH의 차수(Band)를 하나씩 추가한다. 최종적으로 4개의 밴드가 모두 채워질 때까지 이 과정을 반복한다.
Results and Evaluation
저자들은 총 13개의 실제 장면과 합성 데이터셋(Blender)을 통해 3DGS의 성능을 검증했다. 비교 대상은 Mip-NeRF360, InstantNGP, Plenoxels이다.

위 표를 보면, Mip-NeRF360이 48시간 동안 학습해서 얻은 품질을, 3DGS는 단 41분 만에 거의 따라잡았다. 렌더링 속도는 무려 2000배 이상 빠르다(10초/프레임 vs 134 FPS).
InstantNGP 같은 빠른 방식들은 학습을 더 해도 품질이 정체되지만, 3DGS는 학습 시간을 7K에서 30K로 늘릴수록 SOTA(State-of-art) 품질에 도달한다.

합성 데이터(Blender)에서는 더욱 놀랍다. 배경이 없는 합성 장면에서는 SfM 포인트 없이 10만 개의 랜덤 가우시안으로 시작해도 SOTA 품질을 달성한다. 합성 장면 렌더링 속도는 180~300FPS에 달한다. 즉, '실시간 추론'이 완성되었음을 보여준다.

아래 표는 각 알고리즘 요소가 빠졌을 때 성능이 얼마나 처참해지는지 보여준다.

- Limited-BW(정렬 제한) : 그래디언트를 받는 가우시안 수를 제한하면 PSNR이 10dB 이상으로 폭락한다. (Truck-30K 기준 24.81 --> 13.84)
- Isotropic(구형 가우시안) : 럭비공 모양(Anistropic)을 포기하고 단순한 '구형'을 쓰면 평균 PSNR이 약 1dB 하락한다. 이는 디테일 표현에 비등방성이 필수임을 의미한다.
- No-Clone/No-Split : 밀도 제어를 포기하면 수렴 속도가 느려지고 품질이 크게 떨어진다.
Limitations & Conclusions
3D Gaussian Splatting은 기존의 상식을 뒤엎으며 3D 장면 복원의 역사에 한 획을 그은 수준이다. 그동안 학계에서는 고품질의 영상을 얻기 위해 NeRF처럼 공간을 함수로 정의하는 연속적인 표현 방식이 필수적이라고 믿어왔지만, 이 연구는 명시적인 가우시안 프라이머티브만으로도 충분히 빠르고 정교한 학습이 가능하다는 것을 멋지게 증명해냈다. 이 선택 덕분에 최적화 과정에서는 볼륨 랜더링의 이점을 챙기면서도, 실제 그리기 단계에서는 GPU의 힘을 빌려 초고속으로 이미지를 굽는 '스플랫 기반 래스터화'를 구현할 수 있게 된 것이다. 결과적으로 다양한 장면과 촬영 환경에서도 실시간으로 고화질 렌더링을 구현한 최초의 접근법이 탄생했으며, 학습 시간 또한 기존의 가장 빠른 방법들과 어깨를 나란히 할 정도로 단축되었다.
하지만 모든 기술이 그렇듯 역시나 해결해야할 명확한 한계를 가지고 있다. 우선 장면이 충분히 관측되지 않은 구역에서는 어김없이 아티팩트가 발생하며, 때로는 가우시안이 너무 길게 늘어지거나 얼룰덜룩하게 보이는 현상이 생기기도 한다. 특히 큰 가우시안이 생성될 때 화면에 갑자기 나타나는 듯한 '팝핑(Popping)' 현상은 래스터라이저의 단순한 가시성 알고리즘이나 컬링 방식 때문인데, 이는 향후 안티앨리어싱이나 더 정교한 정규화 기법을 통해 개선되어야할 과제이다. 또한 3DGS는 명시적인 데이터를 저장해야 하므로 NeRF 계열보다 메모리 소비가 훨씬 크며, 대규모 장면 학습 시에는 GPU 메모리가 20GB를 넘기기도 한다.
저자들은 포인트 클라우드 압축 기술을 가우시안 표현볍에 이식하는 연구가 매우 흥미로울 것이라고 직접 언급하며 새로운 가능성을 열어두었다. 경량화와 양자화 기술을 이용해 모델의 품질은 유지하면서 수백 MB에 달하는 가우시안 데이터의 무게를 획기적으로 줄여낸다면, 좋은 연구가 될 것 같다.
'Paper Review > 3D Vision' 카테고리의 다른 글