-
[Paper Review] Panoptic Segmentation (Kirillov et al., 2019)Paper Review/3D Vision 2026. 4. 9. 01:41
컴퓨터 비전의 가장 궁극적인 목표 중 하나는 영상 내의 모든 픽셀이 무엇을 의미하는지 완벽하게 파악하는 '장면 이해(Scene Understanding)'에 있다. 하지만 오랫동안 이 분야는 대상을 바라보는 관점에 따라 두 가지 갈래로 나뉘어 발전해 왔다.
하나는 하늘, 도로, 풀밭처럼 일정한 형태가 없고 경계가 모호한 '배경' 요소들에 집중하는 Semantic Segmentation이고,
다른 하나는 사람, 자동차, 도구처럼 개별적으로 개수를 셀 수 있는 '물체'들을 찾아내어 각각의 형태를 구분하는 Instance Segmentation이다.논문의 저자들은 이처럼 배경(Stuff)과 물체(Things)를 분리해서 다루던 기존의 방식이 실세계의 복잡한 장면을 온전히 이해하는 데 한계가 있다고 지적하며, 이 둘을 하나로 통합한 Panoptic Segmentation을 제안한다.
여기서 '파놉틱(Panoptic)'이라는 단어는 "한눈에 모든 것을 본다"는 의미를 담고 있다. 이름에서 알 수 있듯이 이 기술은 이미지 안의 모든 픽셀에 대해 그것이 어떤 범주(Class)에 속하는지 식별함과 동시에, 만약 그것이 물체라면 몇 번째 개체(Instance ID)인지까지 동시에 부여하는 통합적인 시각을 제공한다. 이는 자율주행 자동차가 도로라는 배경 위에서 움직이는 개별 차량과 보행자를 동시에 완벽히 파악해야 하는 것처럼, 실제 환경에서 작동하는 시각 시스템에 있어 필수적인 단계라고 할 수 있다.

저자들은 서론에서 이러한 개념적 분리가 일어난 역사적 배경을 짚어준다.
초창기 컴퓨터 비전은 주로 셀 수 있는 '물체'에 집중했으나, 아델슨(Adelson) 등의 선구적인 연구자들은 형태가 없는 '배경'을 인식하는 시스템의 중요성을 역설했다. 이러한 흐름은 기술적으로도 큰 격차를 만들었다. 배경을 인식하는 Semantic Segmentation은 이미지 전체의 특징을 훑어내는 FCN(Fully Convolutional Nets) 기반의 알고리즘으로 발전한 반면, 물체를 찾는 Instance Segmentation은 물체가 있을 법한 영역을 먼저 제안받아 그 내부를 정밀하게 분석하는 Region-based 방식, 즉 Mask R-CNN과 같은 구조로 분화되었다. 이렇게 서로 다른 데이터셋과 평가 지표, 그리고 알고리즘을 사용하다 보니 두 분야 사이에는 메울 수 없는 거대한 틈이 생기게 된 것이다.
논문은 이 지점에서 날카로운 질문을 던진다.
"과연 배경과 물체를 화해시킬 수는 없는가? 그리고 이를 위해 가장 효과적인 통합 시각 시스템은 어떤 모습이어야 하는가?"라는 물음이다.
과거 딥러닝 이전 시대에서 '장면 파싱(Scene Parsing)'이나 '홀리스틱 장면 이해'라는 이름으로 통합을 시도한 사례들이 있었지만, 당시에는 이를 객관적으로 평가할 수 있는 적절한 지표나 도전적인 과제가 부족하여 큰 대중성을 얻지 못했다.저자들은 이 문제를 해결하기 위해 파놉틱 품질(Panoptic Quality, PQ)이라는 새로운 평가지표를 도입한다. PQ는 배경과 물체라는 서로 다른 성격의 대상들을 하나의 통일된 수식으로 평가할 수 있게 설계되었으며, 이를 통해 인간과 기계가 이 복잡한 과업을 얼마나 잘 수행하는지 엄밀하게 비교할 수 있는 토대를 마련했다.
결과적이로 이 논문은 단순히 새로운 알고리즘을 하나 더 추가하는 것이 아니라, 시각 인식의 패러다임을 '부분'에서 '전체'로 옮기려는 시도이다. 파놉틱 세그멘테이션(Panoptic Segmentation)은 모든 픽셀에 의미를 부여해야 하므로 Semantic Segmentation보다 정교해야 하며, 동시에 물체들이 서로 겹치지 않는 하나의 일관된 평면을 구성해야 하므로 Instance Segmentation보다 구조적인 정합성을 요구한다.
저자들은 Cityscapes, ADE20k와 같은 방대한 데이터셋을 통해 인간의 인지 능력을 측정하고 기계와의 간극을 분석함으로써, 앞으로의 연구 공동체가 나아가야 할 통합적 시각 이해의 이정표를 제시하고 있다. 이제 해당 내용에 대해 더 자세하게 봐보도록 하자.
Related Work
Semantic Segmentation 데이터셋은 상당한 역사를 갖고 있다. 이들은 비전 분야의 핵심적인 혁신을 주도해왔다. 특히 우리가 현재 사용하는 딥러닝 기반 세그멘테이션의 초석이 된 FCN(Fully-Convolution Nets)과 같은 혁신적인 구조도 와 같은 데이터셋이 있었기 때문에 가능했다고 본다.
과거에는 이미지에서 특징을 추출한 뒤 마지막에 '완전 연결 계층(Fully Connected Layer)'을 붙여 이미지가 무엇인지 분류했다. 하지만 이 방식은 위치 정보를 잃어버린다는 단점이 존재했다. FCN은 이 마지막 계층까지도 '합성곱 계층(Convolutional Layer)'으로 대체하여, 결과물이 하나의 숫자가 아닌 입력 이미지와 대응되는 '공간적 지도(Spatial Map)' 형태가 되도록 만들었다. 덕분에 우리는 픽셀 하나하나가 어떤 클래스인지 위치를 유지하며 맞출 수 있게 된 것이다.
전통적인 Semantic Segmentation Dataset들은 이미지 내에 배경(Stuff)과 물체(Thing) 클래스를 모두 포함하고 있다. 하지만 결정적인 차이점은 개별적인 물체의 개별성, 즉 '인스턴스'를 구분하지 않는다는 점에 있다. 예를 들어 길거리에 다섯 명의 사람이 있다면, Semantic Segmentation은 그 다섯 명을 모두 하나의 '사람'이라는 색상 덩어리로 칠해버린다.
이것이 바로 이 논문이 해결하고자 하는 '분열' 지점이다. Semantic Segmentation은 세상을 클래스 단위의 질감으로만 바라본다. 이때 당시 최근에는 Cityscapes, ADE20k, 그리고 Mapillary Vistas와 같은 거대하고 정교한 데이터셋들이 등장하며 이 분야를 이끌고 있다. 이 데이터셋들은 흥미롭게도 Semantic Segmentation과 Instance Segementation을 모두 지원하며, 각 과업에 대해 별도의 트랙을 운영해 왔다.
Bootstrapping
이 논문의 저자들이 주목한 가장 중요한 사실 중 하나는, 앞서 언급한 최신 데이터셋들이 이미 파놉틱 세그멘테이션(PS)를 수행하는 데 필요한 모든 정보를 담고 있다는 점이다. 즉, 파놉틱 세그멘테이션이라는 새로운 과업을 정의하기 위해 수만 장의 사진을 처음부터 다시 찍고 픽셀을 일일이 칠하는 고된 작업을 반복할 필요가 없다는 의미이다.이를 연구 용어로는 Bootstrapping이라고 부른다. 이미 존재하는 데이터(각 픽셀의 클래스 정보 + 각 물체의 개별 ID 정보)를 새로운 관점에서 결합하고 재해석함으로써 새로운 학문적 지평을 여는 것이다. 결과적으로 파놉틱 세그멘테이션은 기존의 Semantic Segmentation이 가진 '배경 이해' 능력과 Instance Segementation이 가진 '개별 물체 파악' 능력을 결합하여, 이미지 내의 모든 가시적인 영역을 단 하나의 통합된 형식으로 설명해 낸다.
멀티테스크 러닝과 파놉틱 세그멘테이션의 결정적 차이
최근 딥러닝의 성공에 힙입어 하나의 거대한 신경망이 여러 가지 시각 문제를 동시에 해결하는 '멀티 태스크 러닝(Multitask Learning)'에 대한 관심이 매우 뜨겁다. 예를 들어 UberNet과 같은 모델은 하나의 네트워크 물체 검출과 시멘틱 세그멘테이션 등 저수준부터 고수준까지의 다양한 과업을 한꺼번에 수행하곤 한다. 하지만 저자들은 파놉틱 세그멘 테이션이 이러한 멀티태스크 문제와는 근본적으로 궤를 달리한다고 강조한다.멀티태스크 설정에서는 각 Task의 출력 결과가 서로 독립적일 수 있기 때문에, 배경(Stuff)을 담당하는 부분과 물체(Things)를 담당하는 부분이 동일한 픽셀에 대해 서로 모순되는 결과를 내놓을 위험이 있다. 반면 파놉틱 세그멘테이션은 이미지 전체를 단 하나의 정합성 있는 장면으로 해석하여, 픽셀 하나하나가 단 하나의 논리적인 결론에 도달하도록 요구하는 통합된 시각을 지향한다.
이 개념은 3D 비전 연구에서도 매우 중요하다.
예를 들어 자율주행차가 2D 이미지 기반으로 도로의 깊이(Depth)를 추정하면서 동시에 물체를 인식할 때, 만약 두 정보가 일치하지 않으면 3D 공간상에서 물체의 위치가 왜곡될 수 있다. PS가 추구하는 '단일하고 일관된 장면 분할'은 바로 이러한 데이터 간의 충돌을 원칙적으로 차단하려는 시도라고 볼 수 있다.Joint Segmentation Task
사실 장면 전체를 하나로 이해하려는 시도는 딥러닝 이전 시대에도 '이미지 파싱(Image Parsing)'이나 '홀리스틱 장면 이해'라는 이름으로 활발히 논의되었다. 당시에는 베이이지언 프레임워크나 그래픽 모델을 활용해 배경과 물체를 동시에 모델링하려는 선구적인 연구들이 있었다. 그럼에도 불구하고, 이러한 흐름이 주류로 자리 잡지 못한 이유는, 모든 연구자가 합의할 수 있는 명확한 Task 정의가 없었고 연구마다 서로 다른 출력 형식과 평가지표를 사용했기 때문이다.본 논문은 이러한 과거의 아쉬움을 극복하고 해당 연구 방향을 다시 부활시키는 것을 목표로 한다. 과거의 연구들이 배경과 물체에 대해 서로 다른 평가지표를 사용하여 성능을 측정했다면, PS는 배경과 물체 모두를 아우르는 '통합된 형식'과 '통일된 지표(PQ)'를 제시함으로써 연구자들이 객관적으로 경쟁하고 발전할 수 있는 토대를 마련했다. 이는 학계에서 새로운 연구 분야가 정착하기 위해서는 단순한 아이디어를 넘어, 공정한 평가의 기준이 얼마나 중요한지를 잘 보여주는 대목이다.
Amodal segmentation task
마지막으로 저자들은 '아모달 세그멘테이션(Amodal Segmentation)'과의 관계를 설명하며 연구의 범위를 명확히 한다.아모달 세그멘테이션이란 물체가 다른 사물에 가려져 있더라도 가려진 부분까지 포함한 전체 영역을 추정하는 방식이다. 본 논문에서 제안하는 Panoptic Segmentation은 현재 눈에 보이는 '가시적인 영역'의 분할에 집중하고 있다. 하지만 가려진 부분까지 포함하는 아모달 설정으로 PS를 확장하는 것은 향후 매우 흥미로운 연구 방향이 될 것이라고 덧붙인다.
Panoptic Segmentation Format
파놉틱 세그멘테이션의 Task 형식은 수식으로 표현하면 매우 간단하면서도 강력한 힘을 가진다.
미리 정의된 $L$개의 시멘틱 클래스 집합 $\mathcal{L} = \{0,.....,L-1\}$ 이 주어졌을 때, PS 알고리즘은 이미지의 각 픽셀 $i$를 $(l_i, z_i) \in \mathcal{L} \times \mathbb{N}$이라는 한 쌍의 값으로 매핑해야 한다.여기서 $l_i$는 해당 픽셀의 시멘틱 클래스를 나타내며, $z_i$는 그 픽셀이 속한 구체적인 인스턴스 아이디(Instance ID)를 의미한다. 같은 클래스이면서 동일한 $z_i$ 값을 가진 픽셀들은 하나의 독립된 물체로 묶이게 되며, 이는 정답지(Ground Truth)와 알고리즘 출력물 모두에서 동일한 규칙을 따른다. 또한, 클래스를 확정할 수 없거나 범위를 벗어난 픽셀들을 위해 '보이드(Void)'라는 특별한 라벨을 할당할 수 있도록 설계하여 현실적인 모호성까지 고려하고 있다.
이 형식 내에서 우리는 배경(Stuff)과 물체(Thing)를 구분하는 아주 영리한 전략을 발견할 수 있다.
전체 클래스 집합 $\mathcal{L}$은 서로 겹치지 않는 두 부분집합인 $\mathcal{L}^{St}$(배경)와 $\mathcal{L}^{Th}$(물체)로 나뉜다. 만약 어떤 픽셀이 배경 클래스($l_i \in \mathcal{L}^{St}$)에 속한다면, 그 픽셀의 인스턴스 아이디인 $z_i$는 아무런 의미를 갖지 않게 된다. 즉, 하늘이나 도로 같은 배경 요소들은 이미지 안에서 단 하나의 거대한 덩어리로 간주되는 것이다. 반대로 자동차나 사람 같은 물체 클래스($l_i \in \mathcal{L}^{Th}$)의 경우에는 동일한 클래스 내에서도 $z_i$ 값에 따라 서로 다른 개체로 엄격히 구분된다. 어떤 클래스를 배경으로 둘지, 혹은 물체로 둘지는 데이터셋 제작자의 설계 의도에 달려 있으며, 이는 기존의 인식 시스템들이 가졌던 유연성을 그대로 계승한 것이다.이러한 포맷의 정의는 기존의 시맨틱 세그멘테이션과의 관계를 통해 더욱 명확해진다. 사실 파놉틱 세그멘테이션은 시멘택 세그멘테이션의 형식을 엄격하게 일반화(Strict Generalization)한 것이다. 두 과업 모두 모든 픽셀에 시맨틱 라벨을 부여해야 한다는 점은 동일하지만, 만약 데이터셋에 인스턴스 정보가 아예 없거나 모든 클래스가 배경(Stuff)뿐이라면 PS와 시맨틱 세그멘테이션의 포맷은 완전히 일치하게 된다. 하지만 PS는 여기서 한 걸음 더 나아가, 이미지 내에 여러 개체가 존재할 수 있는 물체(Thing) 클래스를 포함함으로써 시맨틱 세그멘테이션이 놓치고 있던 '개별성'의 문제를 우아하게 해결한다.
반면, 인스턴스 세그멘테이션과의 관계는 '중첩(Overlap)'이라는 키워드를 통해 극명한 차이를 보인다.
인스턴스 세그멘테이션은 이미지 내의 각 물체를 찾아내어 마스크를 씌우는 것이 목적이기에, 알고리즘이 에측한 사물들이 서로 겹치는 것을 허용한다. 하지만 파놉칙 세그멘테이션은 구조적으로 각 픽셀에 단 하나의 시맨틱 라벨과 단 하나의 인스턴스 아이디만 허용하기 때문에, 어떠한 경우에도 결과물이 서로 겹칠 수 없다.이러한 '비중첩성'은 매우 중요한 물리적 의미를 갖는다. 현실 세계의 물체는 동일한 공간을 동시에 점유할 수 없으므로, PS가 제공하는 평면적이고 일관된 장면 해석은 3D 공간 재구성이나 물체 간의 가림 현상(Occlusion)을 분석하는 데 있어 훨씬 더 강력한 논리적 근거를 제공하기 때문이다.
시멘택 세그멘테이션과 마찬가지로, 파놉틱 세그멘테이션 Task에서는 각 세그먼트와 결합된 신뢰도 점수를 별도로 요구하지 않는다. 이는 얼핏 사소해 보일 수 있지만, 인간과 기계 사이의 '대칭성(Symmetry)'을 확보한다는 측면에서 매우 거대한 의미를 가진다. 기계는 계산을 통해 확률값을 뽑아낼 수 있지만, 인간 어노테이터( Annotator)에게 이미지의 픽셀을 칠하게 하면서 "이 픽셀이 사람일 확률을 소수점 둘째 자리까지 적으세요"라고 요구하는 것은 불가능에 가깝다. 따라서 신뢰도 점수를 요구하지 않음으로써, 기계와 인간이 똑같이 '이미지 주석(Annotation)'이라는 동일한 형태의 결과물을 생성하도록 만든 것이다.
이러한 대칭성은 연구자에게 아주 귀중한 이점을 제공하는데, 바로 ;인간 일관성(Human Consistency)'을 측정하기가 매우 단순해진다는 점이다. 인스턴스 세그멘테이션의 경우, 인간은 명시적인 신뢰도 점수를 제공하지 않기 때문에 정밀도-재현율(Precision-Recall) 곡선을 완벽하게 그리거나 기계와 직접 비교하는 연구가 쉽지 않았다. 하지만 파놉틱 세그멘테이션에서는 기계의 결과물과 인간의 결과물이 완벽히 같은 형식을 취하게 되므로, 우리가 뒤이어 살펴볼 PQ(Panoptic Quanlity) 지표를 통해 인간이 얼마나 정확하게 세상을 나누는지, 그리고 기계가 인간의 수준에 얼마나 접근했는지를 직접적으로 비교할 수 있는 토대가 마련된다.
물론 저자들은 현실적인 유용성 또한 놓치지 않았다. 비록 Task의 기본 정의에서는 신뢰도 점수를 요구하지 않지만, 실제 자율주행이나 증강현실(AR) 같은 하류 시스템(Downstream system)에서는 정보의 불확실성을 파악하는 것이 매우 중요할 수 있다. 예를 들어 자율주행 자동차가 도로 위의 물체를 인식할 때, 그 물체가 무엇인지에 대한 확신이 낮다면 더욱 보수적으로 운전해야 하기 때문이다. 따라서 특정 설정에서는 PS 알고리즘이 신뢰도 점수를 생성하도록 만드는 것이 여전히 바람직할 수 있다는 유연한 견해를 덧붙인다.
즉, 이 대목은 기계 학습의 평가지표를 설계할 때, 그것이 얼마나 인간의 인지 구조와 닮아 있는지를 고민한 흔적이라고 할 수 있겠다.
Panoptic Segmentation Metric
기존의 평가지표들은 시멘틱 세그멘테이션이나 인스턴스 세그멘테이션 중 어느 한 쪽에만 특화되어 설계되었다. 시맨틱 세그멘테이션은 픽셀의 정확도에 집중하고, 인스턴스 세그멘테이션은 개별 물체를 얼마나 잘 검출했는 지를 중시하다보니, 배경(Stuff)과 물체(Thing)가 공존하는 파놉틱 세그멘테이션의 통합적 성격은 온전히 담아낼 수 없었다. 과거의 연구들은 배경은 시맨틱 지표로, 물체는 인스턴스 지표로 각각 따로 평가하는 일종의 편법을 사용해 왔으나, 이는 알고리즘 개발을 복잡하게 만들고 연구자들 사이의 원활한 소통을 방해하는 커다란 걸림돌이 되었다.
따라서 저자들은 이 분야의 새로운 표준이 될 평가 지표를 설계하면서 세 가지 핵심적인 원칙, 즉 '데시데라타(Desiderata, 요구사항)'를 설정한다.
첫 번째는 완전성(Completeness)으로, 배경과 물체 클래스를 통일된 방식으로 처리하여 과업의 모든 측면을 포착해야 한다는 것이다.
두 번째는 해석 가능성(Interpretability)이다. 지표의 숫자가 직관적인 의미를 가져야만 연구자들이 결과의 성패를 명확히 이해하고 소통할 수 있기 때문이다.
마지막은 단순성(Simplicity)으로, 정의와 구현이 쉬워야 투명성이 높아지고 빠른 실험과 재현이 가능해진다.이러한 철학적 기반 위에서 탄생한 것이 바로 PQ이다. PQ는 예측된 세그멘테이션이 정답지(Ground Truth)와 얼마나 유사한지를 측정하며, 크게 두 단계의 과정을 거친다.
첫 번째 단계는 예측된 세그먼트와 정답 세그먼트를 짝짓는 세그먼트 매칭(Segment Matching)이고,
두 번째 단계는 이 매칭 결과를 바탕으로 최종적인 PQ 값을 계산하는 과정이다.Segment Matching
Computer Vision 연구에서 모델이 예측한 결과가 정답과 얼마나 유사한지 판단하려면, 먼저 모델이 찾아낸 수많은 '덩어리(Segment)' 중에서 어떤 것이 실제 정답의 어떤 사물과 짝을 이루는지 결정해야 한다. 저자들은 이 매칭 과정에서 IoU(Intersection over Union)가 0.5보다 큰 경우에만 매칭을 인정한다는 규칙을 제시한다.
그렇다면, IoU(Intersection over Union)은 무엇일까?
IoU는 '교집합 나누기 합집합'으로 계산되는 값으로, 두 영역이 얼마나 겹치는지를 0에서 1 사이의 수치로 나타낸다. 저자들이 설정한 '0.5 초과'라는 기준은 단순히 적당한 숫자를 고른 것이 아니라, 수학적으로 유일한 매칭(Unique Matching)을 보장하기 위한 전략적 선택이다. 논문에서 제시한 'Theorem 1'에 따르면,이미지의 모든 세그먼트가 서로 겹치지 않는 파놉틱 세그멘테이션 특성상, 하나의 정답 세그먼트($g$)에 대해 IoU가 0.5를 넘는 예측 세그먼트($p$)는 단 하나만 존재할 수밖에 없다.
이 원리를 증명하는 과정은 마치 피자 조각을 나누는 것과 비슷하다.
어떤 정답 영역 $g$에 대해 두 개의 예측 영역 $p_1$과 $p_2$가 있다고 가정할 때, 이 둘은 서로 겹치지 않으므로, 그들이 $g$와 겹치는 부분의 합은 절대로 $g$의 전체 크기를 넘을 수 없다. 따라서 만약 $p_1$이 $g$의 50%를 넘게 차지했다면($IoU > 0.5$), $p_2$는 아무리 애를 써도 50% 미만밖에 차지할 수 없게 된다. 결과적으로 복잡한 최적화 알고리즘을 동원하지 않고도, 우리는 아주 빠르고 명확하게 정답과 예측 사이의 1대 1 매핑 관계를 찾아낼 수 있게 된다.이러한 매칭 규칙이 확립되면, 우리는 이제 이미지 속의 모든 사물들을 세 가지로 분류할 수 있다. 아래 그림에서 잘 보여주듯, 정답과 성공적으로 짝을 찾은 예측은 진양성(True Positives, TP)이 되고, 모델이 찾지 못한 실제 사물은 위음성(False Negatives, FN), 그리고 실제로는 없는데 모델이 멋대로 만들어내는 유령 세그먼트는 위양성(False Positives, FP)으로 정의된다. 예를 들어 이미지 속에 사람이 세 명이 있는데, 모델이 두 명만 정확히 찾고 하나는 엉뚱한 곳에 그렸다면, 두 명의 TP와 한 명의 FN, 그리고 한 개의 FP가 발생하는 식이다.

저자들이 이처럼 단순하고 효율적인 매칭 방식을 고집한 이유는 연구의 투명성과 효율성 때문이다. 기존의 복잡한 평가지표들이 매칭 문제를 풀기 위해 이분 그래프 최적화(Maximum Weighted Bipartite Matching) 같은 어려운 수학적 문제에 매달렸던 것과 달리, PQ는 누구나 쉽게 구현하고 이해할 수 있는 직관적인 구조를 가진다. 또한 실제 실험 결과에서도 IoT가 0.5 이하인 매칭은 현실적으로 매우 드물기 때문에, 이 엄격한 기준이 지표의 신뢰성을 떨어뜨리지 않는다는 점도 확인되었다.
PQ Computation
PQ는 각 클래스에 대해 독립적으로 계산된 후, 모든 클래스에 대해 평균을 내는 방식을 취한다. 이러한 방식은 빈도가 낮은 클래스가 전체 성적에 묻히지 않도록 하여 클래스 불균형 문제에 민감하지 않게 만들어준다. 앞서 설명한 매칭 과정을 거치고 나면, 각 클래스의 세그먼트들은 매칭에 성공한 쌍인 진양성(TP), 매칭되지 않은 예측인 위양성(FP), 그리고 매칭되지 않은 정답인 위음성(FN)이라는 세 가지 집합으로 분류된다. 이 세 집합을 바탕으로 정의된 PQ의 기본 수식은 다음과 같다.
$$PQ = \frac{\sum_{(p,g) \in TP} \text{IoU}(p,g)}{|TP| + \frac{1}{2}|FP| + [cite_start]\frac{1}{2}|FN|}$$위 수식은 언뜻 복잡해 보이지만, 뜯어보면 매우 직관적이다. 분자는 매칭에 성공한 세그먼트들의 IoU 합계로, 모델이 물체의 형태를 얼마나 잘 맞췄는지를 나타낸다. 분모에서는 매칭된 개수 ($|TP|$)에 더해, 짝을 찾지 못한 나머지 오류들($|FP|, |FN|$)에 대해 벌점(Penalty)을 부여하는 구조를 가진다. 여기서 흥미로운 점은 모든 세그먼트가 물체의 크기에 상관없이 동일한 중요도를 가진다는 것인데, 이는 거대한 배경뿐만 아니라 아주 작은 사물 하나하나를 정확히 인식하는 것이 중요하다는 연구진의 철학이 담긴 대목이다.
성능 분해: 분할 품질(SQ)과 인식 품질(RQ)
PQ의 진정한 가치는 이 지표가 두 가지 의미 있는 하위 지표의 곱으로 분해될 때 더욱 빛을 발한다. 저자들은 PQ 수식에 $|TP|$를 곱하고 나누는 과정을 통해 이를 분할 품질(Segmentation Quality, SQ)과 인식 품질(Recongnition Quality, RQ)의 곱으로 재정의 한다.
여기서 SQ는 매칭된 세그먼트들의 평균 IoU를 의미하며, 모델이 물체의 경계를 얼마나 세밀하게 묘사했는지를 평가한다. 반면 RQ는 우리가 정보 검색 분야에서 흔히 사용하는 $F_1 \text{score}$와 동일한 형태를 띄며, 모델이 실제 사물들을 빠뜨리지 않고 적절히 찾아냈는지를 측정한다. 이처럼 $PQ = SQ \times RQ$로 분석하게 되면, "우리 모델은 물체는 기막히게 잘 찾는데(높은 RQ), 경계선 처리가 뭉툭하구나(낮은 SQ)"와 같은 구체적인 진단이 가능해진다. 다만 주의할 점은 SQ가 오직 매칭에 성공한 세그먼트들(TP)만을 대상으로 측정되기 때문에, 두 지표가 완전히 독립적인 것은 아니라는 점이다.
현실적인 예외 처리: Void와 Group 라벨
이론적인 수식만큼 중요한 것이 실제 데이터셋의 불완전함을 다루는 방식이다. 현실의 이미지에는 클래스를 특정하기 어려운 모호한 픽셀들이나, 너무 빽빽하게 모여 있어 개별 분리가 힘든 사물들이 존재한다. 저자들은 이를 위해 'Void'와 'Group' 라벨에 대한 명확한 가이드를 제시한다.우선 Void Label은 범위를 벗어난 픽셀이나 모호한 영역에 부여되는데, 평가 시에는 모델의 예측이 이 보이드 영역을 침범하더라도 불이익을 주지 않는다. 매칭 단게에서 예측 세그먼트 중 보이드 픽셀에 해당하는 부분을 제거하고 IoU를 계산하며, 매칭되지 않은 예측이라도 일정 비율 이상이 보이드 픽셀로 구성되어 있다면 이를 위양성(FP)으로 간주하여 벌점을 매기지 않는다.
마찬가지로 인접한 사물들이 너무 많아 개별 구분이 어려울 때 사용하는 그룹 라벨에 대해서도 유연한 기준을 적용한다. 그룹 영역은 매칭 과정에서는 사용되지 않지만, 매칭에 실패한 예측 세그먼트가 그룹 영역 내에 많이 포함되어 있다면 이 역시 FP에서 제외함으로써 알고리즘이 억울하게 낮은 점수를 받는 일을 방지한다. 이러한 세심한 설계는 파놉틱 세그멘테이션이 실험실 환경을 넘어 실제 복잡한 도로 상황이나 실내 환경을 이해하는 데 적합한 도구가 되도록 만들어준다.
이제 이걸 알았으니, 연구를 진행하다 단순히 PQ 점수가 높다는 결과에 만족하기 보다, 알고리즘이 SQ와 RQ 중 어떤 지점에서 혁신을 이루었는지 설명이 가능해야 할 것 같다.
Comparison to Existing Metrics
먼저 전통적인 시멘틱 세그멘테이션에서 흔히 쓰이는 픽셀 정확도(Pixel accuracy), 평균 정확도(Mean accuracy), 그리고 IoU(Intersection over Union)를 살펴보자. 이러한 지표들은 오직 '픽셀' 단위의 출력물과 라벨에만 기반하여 계산될 뿐, 개별 물체라는 '인스턴스' 수준의 정보는 완전히 무시한다. 예를 들어 시맨틱 세그멘테이션에서의 IoU는 특정 클래스에 대해 전체 정답 픽셀과 예측 픽셀 사이의 비율을 따질 뿐이다. 따라서 이 지표들은 개별 사물을 식별해야 하는 '물체(Thing)' 클래스를 평가하기에는 구조적으로 적합하지 않다.
여기서 한 가지 혼동하기 쉬운 지점이 있는데, 바로 시맨틱 세그멘테이션의 IoU와 파놉틱 세그멘테이션의 분할 품질(SQ) 사이의 관계이다. 시맨틱 IoU는 클래스 전체의 픽셀 합계를 기준으로 삼는 반면, SQ는 앞서 설명한 '매칭된 개별 세그멘트들'의 IoU 평균을 구한다는 점에서 근본적으로 다르다. 즉 PQ는 이미지 전체의 픽셀 뭉텅이가 아니라, 하나하나 독립된 객체들을 얼마나 정미랗게 찾아냈는지를 중시하는 지표라고 볼 수 있다.
다음으로 인스턴스 세그멘테이션의 표준 지표인 평균 정밀도(Average Precision, AP)와의 비교를 통해 PQ의 특성을 더 명확히 알 수 있다. AP를 계산하기 위해서는 각 객체 세그먼트가 '신뢰도 점수(Confidence score)'를 가지고 있어야 하며, 이를 통해 정밀도-재현율(Precision-Recall) 곡선을 그려야 한다. 3D 비전에서도 물체 검출 모델을 평가할 때 가장 많이 쓰이는 방식이지만, 시맨틱 세그멘테이션에서는 이러한 신뢰도 점수를 사용하지 않는 것이 일반적이다.
이러한 특성 때문에 AP는 시맨틱 세그멘테이션이나 파놉틱 세그멘테이션의 결과를 측정하는 도구로 쓰일 수 없다. 파놉틱 세그멘테이션은 모든 픽셀에 대해 단 하나의 명확한 결과를 내놓는 Task이지, 확률적인 후보군들을 나열하는 Task가 아니기 때문이다. 따라서 저자들은 신뢰도 점수에 의존하지 않으면서도 인스턴스 수준의 성능을 측정할 수 있는 PQ를 통해, 인간과 기계가 동일한 선상에서 평가받을 수 있는 환경을 구축했다.
결국 파놉틱 품질(PQ)은 배경(Stuff)과 물체(Thing)라는 서로 다른 성격의 대상을 단 하나의 통일된 방식으로 처리하는 유일한 지표이다. 여기서 주의 깊게 보아야 할 부분은 PQ가 단순히 시맨틱 지표와 인스턴스 지표를 적당히 섞어 놓은 하이브리드 지표가 아니라는 점이다. 오히려 배경과 물체라는 모든 클래스에 대해 동일하게 SQ(분할 품질)와 RQ(인식 품질)를 계산함으로써, 이미지 내의 모든 구성 요소를 동등한 가치로 평가한다.
Panoptic Segmentation Datasets
Cityscapes
Cityscapes는 자율 주행 연구에서 많이 쓰이는 데이터셋이다. 주로 유럽의 도심 환경에서 촬영된 주행 영상들을 담고 있으며, 총 5000장의 이미지로 구성되어 있다. 이 데이터셋의 특징은 이미지 내 픽셀의 97%가 매우 정교하게 라벨링되어 있다는 점인데, 전체 19개의 클래스 중에서 8개가 개별 물체를 구분하는 '인스턴스' 수준의 정보를 포함하고 있다.
ADE20k
도심 주행에 특화된 Cityspaces와 달리, ADE20k는 우리가 일상에거 마주하는 거의 모든 장면을 아우르는 방대한 규모를 자랑한다. 25000장이 넘는 이미지들은 실내외를 가리지 않고 매우 다양하게 구성되어 있으며, 원래는 단어장 형식의 개방형 라벨을 지향한다. 본 연구에서는 '2017 Places Challenge'의 기준에 따라 전체 픽셀의 89%를 커버하는100개의 물체(Thing) 클래스와 50개의 배경(Stuff) 클래스를 선정하여 사용했다. 이 데이터셋은 장면의 복잡도가 매우 높기 때문에, 모델의 범용적인 인식 능력을 테스트하기에 안성맞춤이다.
Mapillary Vistas
마지막으로 Mapillary Vistas는 전 세계의 다양한 거리 뷰를 담고 있는 독보적인 데이터셋이다. 25000장의 이미지는 전 세계 곳곳에서 다양한 해성도로 촬영되어 데이터의 다양성이 매우 높다. 픽셀 커버리지는 98%에 달하며, 특히 28개의 배경 클래스와 37개의 물체 클래스를 제공하여 파놉틱 세그멘테이션 과업을 수행하기에 가장 이상적인 구성을 갖추고 있다.
Human Consistency Study
저자들은 먼저, 인간 수행 능력을 평가했다. 인간 수행 능력은 어떻게 보면, 기계가 도달해야 하는 일종의 가이드라인이자, 해당 과업이 가진 본질적인 난이도를 파악하는 척도가 되기 때문이다.
알고리즘이 내놓는 결과는 특정 설계 방식이나 모델의 편향(Bias)에 의해 왜곡될 수 있지만, 인간의 결과물을 분석하면 과업 자체가 가진 '태생적인 어려움'을 가감 없이 들여다볼 수 있기 때문이다. 또한 앞서 설명한 PQ(Panoptic Quality) 지표가 실제 인간의 인지 체계와 얼마나 잘 부합하는지 검증하고, 기계의 성능이 어느 지점에 와 있는지 '영점 조절(Calibration)'을 하는 데 필수적이다.
연구진은 이 실험을 위해 Cityspaces 30장, ADE20k 64장 그리고 Vistas 46장의 '이중 주석(Doubly annotated)' 이미지를 준비했다. 여기서 Cityspaces와 Vistas는 서로 다른 두 명의 사람이 독립적으로 같은 사진을 작업했고, ADE20k는 숙련된 한 명의 작업자가 6개월의 시간 간격을 두고 동일한 이미지를 다시 작업하는 방식을 택했다. 연구진은 두 작업물 중 하나를 정답(Ground Truth)으로, 다른 하나를 예측(Prediction)으로 간주하여 PQ를 계산했다. PQ 지표는 수학적으로 대칭적인 구조를 가지기 때문에 어느 쪽을 정답으로 두어도 결과는 동일하며, 이를 통해 인간들 사이의 '합의 수준'을 측정할 수 있게 됐다.
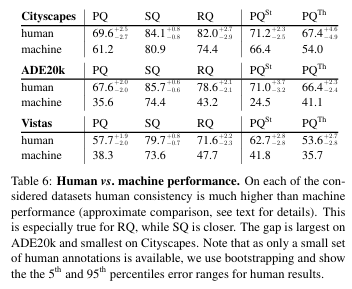
실험 결과는 꽤나 놀라웠다. 아래 표를 보면 인간 역시 완벽하지 않다는 사실이 드러난다.

전체적인 파놉틱 품질(PQ)는 데이터셋에 따라 약 57.5%에서 69.7% 사이로 나타났는데, 이는 인간도 복잡한 장면을 완벽하게 일치하게 해석하기는 어렵다는 것을 보여준다. 여기서 우리가 주목해야 할 점은 배경(Stuff)과 물체(Thing) 사이의 일관성 차이이다. 흔히 물체를 개별적으로 구분하는 것이 훨씬 어려울 것이라 예상하기 쉽지만, 결과적으로 두 클래스 군에 대한 인간의 일관성은 놀라울 정도로 비슷하게 나타났다. 이는 PQ 지표가 배경과 물체의 난이도를 균형 있게 통합하여 측정하고 있다는 강력한 증거이기도 한다.연구진은 인간이 저지르는 실수를 두 가지 유형으로 시각화 했다. 첫 번째는 분할 결함(Segmentation flaws)으로, 아래 그림에서 보듯이 하나의 자동차를 두 개로 나누어 인식하거나 경계선이 모호한 영역에서 서로 다른 판단을 내리는 경우이다. 두 번째는 분류 결함(Classification flaws)이다. 아래 그림(Fig4)처럼 사물의 형태는 정확히 찾아냈지만, 그것이 Tram인지 'building'인지에 대해 서로 다른 라벨을 부여하는 경우이다. 특히 도심의 복잡한 장면에서는 인간조차 정답을 확신하기 어려운 '진정한 의미의 모호성'이 존재한다는 점이 확인되었다.

Stuff vs Things
파놉칙 세그멘테이션의 가장 큰 매력은 배경과 물체를 하나의 틀에서 다룬다는 점이다. 저자들은 배경 클래스에 대한 평균 PQ($PQ^{St}$)와 물체 클래스에 대한 평균 PQ($PQ^{Th}$)를 분리하여 분석했는데, Cityscapes와 ADE20k 데이터셋에서는 인간의 일관성이 두 부류에서 매우 유사하게 나타났다. 비록 Vistas 데이터셋에서는 그 격차가 조금 더 벌어졌지만, 전반적으로 배경과 물체의 인식 난이도는 비슷하며, 물체 클래스가 약간 더 어렵다는 결론에 도달한다. 아래 그림을 보면, 모든 클래스를 PQ 점수 순으로 나열했을 때 배경과 물체가 어느 한쪽으로 치우치지 않고 고르게 분포되어 있음을 확인할 수 있다. 이는 PQ 지표가 특정 유형의 오류에 치우치지 않고 두 과업을 성공적으로 통합했음을 시사한다.
Small vs Large objects
사물의 크기는 인간의 인지 과정에서도 결정적인 변수로 작용한다. 연구진은 각 데이터셋의 물체들을 크기에 따라 하위 25%인 소형(Small), 중간 50%인 중형(Medium), 상위 25%인 대형(Large)으로 나누어 분석했다. 실험 결과 대형 물체에 대해서는 모든 데이터셋에서 인간의 일관성이 상당히 높게 나타났다. 하지만 소형 물체로 갈수록 인식 품질(PQ)이 급격히 떨어지는 현상이 관찰되었다. 이는 인간 작업자조차 아주 작은 물체는 찾아내는 것 자체를 어려워한다는 것을 의미한다. 흥미로운 점은 일단 작은 물체를 찾아내기만 하면, 그것을 정교하게 칠하는 분할 품질(SQ)는 꽤 합리적인 수준을 유지한다는 사실이다.우리는 앞서 IoU가 0.5를 넘어야만 유일한 매칭이 보장된다는 수학적 정리를 배웠다. 하지만 "과연 0.5라는 기준이 실제 데이터에서도 타당한가?"라는 의문이 생길 수 있다. 이를 검증하기 위해 연구진은 임계값 없이 모든 세그먼트를 대상으로 최대 가중치 이분 매칭(Maximum weighted bipartite matching)을 수행해 보았다. 그 결과, 매칭된 객체 중 IoU가 0.5미만인 경우는 16%도 채 되지 않았다. 또한 아래 그림에서 보듯이 임계값을 0.25로 낮추었을 때와 0.5일 때의 PQ 값 차이는 매우 미미했다. 반면 임계값을 0.75로 높이면 PQ 값이 크게 떨어졌다. 낮은 IoU에서의 매칭은 상당수가 잘못된 짝짓기(False matches)일 가능성이 높기 때문에, 수학적으로 유일성을 보장하면서도 직관적인 0.5라는 기준은 매우 합리적인 선택임이 증명되었다.

SQ vs RQ balance
마지막으로 논문은 인식 오류에 대한 패널티를 조절할 수 있는 확장된 수식을 제한한다. 기본적으로 RQ는 $F_1$ score와 동일한 구조를 가지지만, 연구진은 $\alpha$라는 파라미터를 도입하여 이를 일반화했다.$$RQ^{\alpha} = \frac{|TP|}{|TP| + \alpha|FP| + [cite_start]\alpha|FN|}$$
여기서 $\alpha$의 기본값은 0.5이다. 만약 $\alpha$ 값을 낮추면 매칭되지 않은 세그먼트에 대한 패널티가 줄어들어 RQ 점수가 올라가게 된다. 아래 그림은 다양한 $\alpha$값에 따른 SQ와 RQ의 변화를 보여주는데, 기본값인 0.5가 두 지표 사이의 균형을 가장 잘 잡아주고 있음을 알 수 있다. 연구의 목적에 따라 세그먼트의 정밀한 형태가 중요하다면 SQ의 비중을 높이고, 물체를 빠짐없이 찾는 것이 중요하다면 $\alpha$를 조절하여 RQ의 영향력을 바꿀 수 있다.

Machine Performance Baselines
저자들은 파놉틱 세그멘테이션만을 위해 설계된 전용 모델이 아직 부족한 상황에서, 이미 검증된 인스턴스 세그멘테이션 모델과 시맨틱 세그멘테이션 모델을 영리하게 결합하는 방식을 택했다. 예를 들어 Cityscapes 데이터셋에서는 인스턴스 인식을 위해 Mask R-CNN을, 배경 인식을 위해 PSPNet을 사용했다. 이렇게 각각의 분야에서 우승을 차지한 강력한 모델들을 가져와 '휴리스틱(Heuristic)'이라 불리는 일련의 규칙들을 적용해 하나의 파놉틱 출력물로 병합한 것이다.
인스턴스 세그멘테이션 모델은 기본적으로 물체들이 서로 겹치는 것을 허용하며 결과를 내놓는다. 하지만 파놉틱 형식은 겹침을 허용하지 않으므로, 연구진은 이를 해결하기 위해 NMS(Non-Maximum Suppression)와 유사한 절차를 도입했다. 먼저 신뢰도 점수가 높은 순으로 물체들을 정렬한 뒤, 앞선 물체가 이미 점유한 픽셀을 다음 물체가 차지하지 못하도록 깎아내는 방식이다. 만약 이 과정에서 물체의 원래 영역이 너무 많이 사라지면 해당 물체 자체를 삭제해버린다. 실험 결과, 인스턴스 세그멘테이션의 지표인 AP(Average Precision)가 높은 모델이 파놉틱 지표인 PQ 또한 높게 나타나는 경향을 보였다.

시맨틱 성능과 PQ의 관계
이미 겹침이 없는 시맨틱 세그멘테이션의 결과물은 바로 PQ를 계산할 수 있다 아래 표를 보면 일반적으로 평균 IoU(mean IoU)가 높음 모델이 PQ 점수도 높게 나오지만, ADE20k 데이터셋처럼 장면이 복잡한 경우 그 격차가 크게 벌어지기도 한다. 특히 G-RMI 모델의 사례는 매우 흥미로운 시사점을 준다. 이 모델은 이미지에 존재하지 않는 클래스의 작은 파편들을 여기저기 만들어내는 "환각(Hallucination)"증상을 보였는데, 이는 픽셀 단위로 점수를 매기는 IoU에는 큰 타격을 주지 않지만, 인스턴스 단위로 오류를 집계하는 PQ 점수는 심각하게 깎아먹는 결과를 초래했다. 이는 PQ가 단순한 정확도를 넘어 장면의 구조적 정합성을 더 엄격하게 평가함을 보여준다.
파놉틱 병합: 배경과 물체의 충돌 해결
최종적인 파놉틱 결과를 만들기 위해 연구진은 인스턴스 결과와 시맨틱 결과를 하나로 합쳤다. 이때 발생하는 배경과 물체 사이의 픽셀 충돌은 물체가 우선한다.는 간단한 규칙으로 해결했다. 즉 어떤 픽셀이 '도로(배경)'이면서 동시에 '자동차(물체)'로 판정되었다면 자동차의 손을 들어주는 것이다. 아래 표를 보면 이러한 병합 과정을 거친 후 물체의 성능($PQ^{Th}$)은 유지되는 반면, 영역을 물체에 내어준 배경의 성능($PQ^{St}$)은 소폭 하락하는 양상을 보인다.
마지막으로 저자들은 인간과 기계의 PQ 점수를 정면으로 비교했다. 결과는 명확했다. 모델이 물체의 형태를 그려내는 실력인 SQ(분할 품질)은 인간과 상당히 근접한 수준까지 올라왔다. 하지만 그 사물이 무엇인지, 그리고 그곳에 사물이 있는지를 정확히 판단하는 RQ(인식 품질)에서는 기계가 인간에 비해 현저히 낮은 점수를 기록했다. 특히 ADE20k와 같이 사물의 종류가 많은 데이터셋에서 이 격차는 더욱 도드라졌다.

아래 표는 사물을 정확히 식별하고 분류하는 인식 품질(RQ)에서는 기계가 인간에 비해 처참할 정도로 낮은 성적을 거둔 것을 보여준다.
Future of Panoptic Segmentation
이 논문은 컴퓨터 비전에서 '배경'과 '물체'를 분리해서 보던 낡은 관습에서 벗어나, 장면 전체를 통합적으로 바라보는 새로운 연구 방향을 제시했다고 볼 수 있다. 저자들은 이 통합된 과업이 예상하는 또는 예상치 못한 수많은 혁신을 불러일으킬 것이라고 확신한다.
파놉틱 세그멘테이션은 무정형의 배경을 다루는 시맨틱 세그멘테이션과 개별 물체를 구분하는 인스턴스 세그멘테이션을 하나로 통합하여 이미지 내 모든 가시 영역을 중첩없이 식별하는 Task이다. 이 연구는 배경(Stuff)과 물체(Things)를 통일된 방식으로 평가하기 위해 파놉틱 품질(PQ) 지표를 제안했으며, 이는 형태의 정밀도인 SQ와 인식의 정확도인 RQ의 곱으로 정의되어 모델의 성취도를 입체적으로 분석하게 해준다. 인간 일관성 연구를 통해 기계가 사물의 형태를 그리는 능력(SQ)은 인간 수준에 근접했으나, 사물의 정체를 정확히 분류하는 인식 능력(RQ)에서는 여전히 상당한 격차가 있음이 확인되었다.
'Paper Review > 3D Vision' 카테고리의 다른 글