-
[Paper Review] 4D Panoptic LiDAR Segmentation (Aygun et al., 2021)Paper Review/3D Vision 2026. 4. 10. 11:18
자율주행 자동차나 동적인 환경에서 작동하는 로봇에게 있어서 시간적 흐름을 고려한 시각적 이해는 필수적이다. 과거에는 이러한 장면 이해를 위해 여러 가지 기술들이 개별적으로 발전해 왔다. 예를 들어, 모든 점에 대해 '도로'나 '차량' 같은 범주를 정하는 의미론적 분할(Semantic Segmentation), 개별 물체의 위치를 찾는 객체 탐지(Object Detection), 그리고 같은 종류의 물체라도 각각을 구분해내는 인스턴스 세그멘테이션(Instance Segmentation) 등이 대표적이다. 여기에 시간이 더해지면 물체의 궤적을 쫓는 다중 객체 추적(Multi-Object Detection, MOT) 기술이 추가로 필요하게 된다.
이러한 개별 분야들은 딥러닝 기반의 이미지 처리 기술과 포인트 세트(Point-set) 표현 학습, 그리고 대규모 데이터셋의 등장에 힘입어 비약적인 발전을 이루었다. 하지만 최근의 흐름은 이 모든 작업을 하나로 통합하려는 '전체론적 장면 이해(Holistic Scene Understanding)'를 향하고 있다. 그 대표적인 예가 바로 의미론적 분할과 인스턴스 분할을 합친 파놉틱 분할(Panoptic Segmentation)이다.
기존 연구들은 주로 2차원 이미지나 짧은 비디오 클립을 대상으로 파놉틱 분할을 수행해 왔지만, 자율주행차는 센서 데이터를 연속적으로 해석하고 3차원 공간과 시간이 결합된 4차원 연속체(4D Continuum) 내에서 물체의 위치를 정확히 파악해야 한다는 본질적인 요구가 있다.
4D 파놉틱 LiDAR 분할의 제안
이 논문의 저자들은 4D 파놉틱 LiDAR 분할이라는 새로운 과제를 제안한다. 이것은 연속적인 3차원 포인트 클라우드 데이터에 대해 각 점마다 의미론적 클래스(Semantic Class)를 부여함과 동시에, 시간이 지나도 변하지 않는 일관된 인스턴스 ID(Instance ID)를 할당하는 작업이다.여기서 우리가 주목해야 할 기술적 시초는 LiDAR 데이터의 특성이다. LiDAR는 수만 개의 점으로 이루어진 포인트 클라우드를 생성하는데, 기존의 최신 기법들은 메모리 제한 문제 때문에 단일 스캔 데이터 조차 샘플링을 통해 크기를 줄여야 하는 경우가 많다. 이 때문에 기존의 3D 다중 객체 추적은 주로 각 프레임에서 객체를 먼저 찾고(Detection), 이후에 수작업으로 만든 모션 모델을 이용해 시간적으로 연결(Association)하는 '추적 기반 탐지(Tracking-by-detection)' 방식을 사용해 왔다.
하지만 본 논문은 이와는 근본적으로 다른 '통합 시공간 처리(Unified space-time treatment)' 철학을 따른다. 프레임별로 쪼개서 생각하는 것이 아니라, 여러 개의 스캔을 겹쳐서 하나의 4차원 볼륨을 형성하고, 이를 네트워크가 한 번에 통과(Single network pass)하면서 모든 점의 의미와 인스턴스 그룹을 동시에 결정하는 방식이다.

기술적 혁신과 새로운 평가 지표
이 연구의 핵심적인 접근법 중 하나는 물체의 인스턴스를 4차원 시공간 도메인에서의 확률 분포(Probability Distributions)로 모델링하는 것이다. 이를 통해 명시적인 데이터 연결 과정 없이도 클러스터링을 통해 시각적 연관성을 암시적으로 해결할 수 있게 되었다. 이는 추론의 효율성을 유지하면서도 긴 시간 동안의 객체 연관성을 확보하는 데 매우 효과적이다.또한, 연구팀은 이 새로운 과제를 공정하게 평가하기 위해 LSTQ(LiDAR Segmentation and Tracking Quality)라는 새로운 지표를 도입했다. 기존의 지표들은 단순히 객체를 얼마나 잘 인식했느냐에 치중하는 경향이 있었지만, LSTQ는 의미론적 분류 점수($S_{cls}$)와 시공간 연관성 점수($S_{assoc}$)라는 두가지 직관적인 항으로 구성되어 두 측면을 균형 있게 평가한다.
결론적으로 이 논문의 기여는 세 가지로 요약된다.
첫쨰, 탐지, 분할, 추적을 하나의 점 클러스터링 문제로 치환하여 4D LiDAR 파놉틱 분할을 위한 통합된 시공간적 관점을 제시한다.
둘째, 의미론적 이해와 객체 연관성을 공정하게 평가할 수 있는 점 중심의 평가 프로토클을 채택했다.
마지막으로, SemanticKITTI 데이터셋을 활용해 기존 방식들과의 성능을 철저히 분석하고 비교할 수 있는 테스트 환경을 구축했다.이 연구는 단순히 기술적인 정확도를 높이는 것을 넘어, 로봇이 시간을 머금은 3차원 세상을 어떠헥 하나의 완성된 흐름으로 인지할 것인가에 대한 중요한 이정표를 제시하고 있다.
Related Work
자율주행 자동차에 대한 관심이 뜨거워지면서 LiDAR 센서를 이용한 장면 인식 연구 역시 폭발적으로 증가했다. 이러한 발전의 원동력은 크게 두 가지로 요약할 수 있는데, 첫 번째는 포인트 세트(Point sets)에 직접 적용 가능한 딥러닝 기술의 진보이며, 두 번째는 표준화된 벤치마크 데이터셋의 등장이다. 3D 공간의 점들을 어떻게 효율적으로 학습할 것인가에 대한 고민은 PointNet이나 KPConv와 같은 혁신적인 신경망 구조를 낳았고, SemanticKITTI나 nuScenes 같은 대규모 데이터셋은 연구자들이 동일한 기준에서 알고리즘의 성능을 겨룰 수 있는 장을 마련해 주었다. 이러한 흐름은 모바일 로봇 인식 분야에서 공간적(Spatial) 요소와 시간적(Temporal) 요소를 모두 발전시키는 것이 얼마나 중요한지를 다시 한번 확인시켜 주었다.
파놉틱 분할 --> 비디오 영역
최근 이미지 기반 인식 커뮤니티의 가장 큰 화두는 서로 다른 작업들을 하나로 통합하려는 시도이다. 과거에는 물체의 종류를 맞추는 것(Semantic)과 개별 물체를 식별하는 것(Instance)을 따로 생각했지만, 이를 파놉틱 분할(Panoptic Segmentation)이라는 개념으로 통합하며 PQ(Panoptic Quality)라는 평가 지표가 제안되었다.여기서 한 걸음 더 나아가 비디오 데이터에서 다중 객체 추적과 인스턴스 분할을 동시에 수행하는 MOTS(Multi-object Tracking and Segmentation) 연구로 확장되었고, 최근에는 파놉틱 분할 자체가 비디오 도메인으로 확장되기도 했다. 하지만 기존의 비디오 파놉틱 연구들은 주로 짧고 드문드문 레이블이 지정된 비디오 클립을 오프라인 상태에서 해석하는 데 집중되어 있었다. 이는 3D IoU를 기반으로 한 PQ 지표를 시간 윈도우별로 평균 내는 방식을 사용하는데, 안타깝게도 센서 데이터를 실시간으로 끊임없이 해석해야 하는 자율주행 자동차에는 적합하지 않은 설정이다.
자율주행 환경에 맞게 MOTA(Multi-Object Tracking Accuracy)와 PQ를 결합하여 ID 스위치(ID Switch, 추적하던 물체의 번호가 바뀌는 오류)에 대한 패널티를 추가하려는 시도도 있었다. 하지만, MOTA와 PQ 자체도 이미 학계에서 많은 비판을 받아온 지표들이며, 이를 단순히 결합하는 방식은 기존 지표들이 가진 고질적인 문제들을 그대로 상속받게 된다. 예를 들어, 아주 미세한 오차로 물체 매칭에 실패했을 때 가혹하 패널티를 받거나, 한 번 추적을 놓쳤다가 다시 찾았을 때 이를 보상해주는 체계가 부족하다는 점 등이 대표적이다.
이러한 배경 속에서 본 논문의 저자들은 시공간적 LiDAR 데이터에 특화된 새로운 접근 방식을 제안한다.저자들은 시각 기반 다중 객체 추적에서 최근 제안된 HOTA(Higher Order Tracking Accuracy)의 아이디어를 빌려와 LiDAR 파놉틱 분할 영역에 이식했다. 이 방식의 가장 큰 특징은 시공간적인 포인트 클라우드(Spatio-temporal Point Clouds) 위에서 작동한다는 점이다. 즉, 공간의 3차원(x,y,z)에 시간(t)를 더한 4차원 데이터 위에서 객체의 인스턴스를 직접 정의함으로써, 시간적 연속성과 공간적 정확성을 동시에 확보하는 혁신적인 구조를 제안하고 있는 것이다.
Point Cloud Segmentation
포인트 클라우드 세분화는 말 그대로 3차원 공간상의 점(Point) 하나하나에 그것이 무엇인지에 대한 이름을 붙여주는 작업이다. 과거의 전통적인 방식은 연구자가 직접 '점들의 기울기가 어떠한가' 혹은 '주변 점들과의 밀도는 어떠한가'와 같은 특징 추출기(Feature extractor)를 설계하고, 이를 머신러닝 분류기와 결합하여 문제를 해결했다. 특히 주변 점들과의 라벨 일관성을 강제하기 위해 '조건부 무작위장(Conditional Random Fields, CRF)'이라는 통계적 기법을 자주 사용했는데, 이는 이웃한 점들이 가급적 같은 종류로 분류되도록 유도하는 역할을 했다.하지만 S3DIS나 SemanticKITTI와 같은 대규모 3차원 데이터셋이 등장하면서 연구의 판도가 완전히 바뀌었다. 이제는 사람이 특징을 설계하는 대신, 데이터로부터 직접 특징을 배우는 '엔드 투 엔드(End-to-end)' 파이프라인이 주류가 되었다. 본 논문은 이러한 최신 트렌드를 이어받아 아래에서 위로 점들을 묶어 나가는 '바텀업(Bottom-up)' 방식의 데이터 기반 그룹화 기술을 사용한다. 특히 주목할 점은 이 그룹화가 단순히 3차원 공간에서만 일어나는 것이 아니라, 시간 축을 포함한 4차원 시공간에서 동시에 일어난다는 것이다.
이러한 고도의 작업을 수행하기 위해 본 논문은 KPConv라고 불리는 신경망 구조를 백본(Backbone)으로 채택했다. KPConv는 고정된 격자 구조가 없는 포인트 클라우드의 특성에 맞춰, 필터의 위치가 유연하게 변하는 '변형 가능한 포인트 컨볼루션(Deformable point convolutions)'을 적용한다. 연구 결과, 이 방식은 단순히 시간 순서대로 데이터를 처리하도록 설계된 다른 신경망들보다 훨씬 더 뛰어난 성능을 보여주었다.
Multi-Object Tracking and Segmentation
다중 객체 추적(MOT) 분야에서 오랫동안 정석처럼 여겨진 방법론은 탐지 기반 추적(Tracking by detection)이었다. 이는 먼저 각 프레임에서 독립적으로 물체를 찾아낸 뒤, 서로 다른 시간대의 물체들이 '동일한 물체인가'를 따져서 선으로 잇는 방식이다. 과거에는 이 연결 과정을 최적화하기 위해 수학적으로 매우 복잡한 데이터 연관(Data association) 기법들이 연구되었다. 최근에는 이 연결 과정조차 딥러닝으로 학습시키거나, 물체의 목표 위치를 직접 예측하는 방식들이 등장하며 엔드 투 엔드 학습으로 나아가고 있다.로봇 비전 분야에서는 물체가 3차원 공간과 시간 속에서 어떤 궤적을 그리며 움직이는지 정확히 파악하는 것이 생존과 직결된 문제이다. 초기에는 스테레오 카메라를 이용해 위치를 찾거나, 단순히 공간적으로 가까운 점들을 먼저 묶은 뒤 이를 시간에 따라 추적하는 범주 무관(Category-agnostic) 방식이 사용되었다. 이후 LiDAR 전용 3D 객체 탐지기들이 발전하면서 LiDAR 기반의 MOT 연구가 활발해졌는데, 특히 '단순한 선형 할당(Linear assignment)'과 '등속도 운동 모델'만으로도 탐지 결과만 확실하다면 놀라울 정도의 성능을 낼 수 있다는 사실이 증명되기도 하였다.
하지만 이 논문은 이러한 기존의 '공간에서 먼저 찾고, 시간에 따라 잇는' 이분법적 사고 방식에서 완전히 탈피한다. 대신 이미지나 비디오 인스턴스 세분화의 최신성과를 이어받아, 4차원 시공간 볼륨 내에서 물체의 '중심'이 될 법한 지점들을 먼저 찾아낸다. 그리고 그 중심을 기준으로 주변의 점들을 바텀업 방식으로 묶어버림으로써 인스턴스를 식별한다. 이와 동시에 신경망의 또 다른 가지(Branch)에서는 각 점이 어떤 종류(클래스)인지를 할당하는 작업이 병렬적으로 수행된다. 결정적으로 탐지와 추적, 그리고 세분화가 하나의 4차원 공간 안에서 유기적으로 통합되는 셈이다.
이러한 방식은 로봇이 세상을 단순히 '사진의 연속'으로 보는 것이 아니라, '끊임없이 흐르는 공간'으로 인식하게 만드는 아주 중요한 변화라고 할 수 있다.
Method
4D 파놉틱 LiDAR 분할의 목표와 철학
우선 풀어야할 과제는 다음과 같다.
4D 파놉틱 분할의 목표는 연속적인 LiDAR 스캔 데이터가 주어졌을 때, 각 3D 점에 대해 두 가지 정보를 예측하는 것이다.
첫째는 그 점이 '도로'인지 '자동차'인지와 같은 의미론적 라벨(Semantic Label)이고,
둘째는 시간이 지나도 변하지 않고 유지되는 물체의 고유한 인스턴스 ID이다.여기서 중요한 것은 자동차(Thing)와 같은 객체뿐만 아니라 도로(Stuff)같은 배경까지 모두 아우르는 통합적인 이해가 필요하다는 점이다.
이 논문의 저자들은 기존의 '탐지 후 추적(Tracking-by-detection)'이라는 지배적인 패러다임을 과감히 거부한다. 대신 이들은 4D 파놉틱 분할을 두 개의 병렬적인 과정으로 재구성하는데, 하나는 4차원 연속체 내에서 점들을 그룹화하는 클러스터링(Clusterting) 과정이고, 다른 하나는 각 점에 의미를 부여하는 의미론적 해석(Semantic Interpretation) 과정이다. 이 두 과정은 별개의 단계가 아니라 하나의 네트워크 안에서 유기적으로 맞물려 돌아가게 된다.

4D-PLS의 구조: 시공간을 아우르는 네트워크
이 연구에서 제안하는 시스템의 전반적인 흐름은 매우 효율적이다.
먼저 연속적인 여러 개의 LiDAR 스캔을 합쳐 하나의 4차원 포인트 클라우드를 형성한다. 그런 다음, 단 한번의 네트워크 통과(Single network pass)를 통해 네 가지 핵심적인 정보, 즉 물체성 지도(Objectness map, O), 분산 지도(Variance map, $\Sigma$), 포인트 임베딩(Embedding map, $\epsilon$), 그리고 의미론적 지도(Semantic map, S)를 동시에 추출해낸다.여기서 흥미로운 점은 인스턴스를 구분하는 방식이다. 이미지나 비디오 분야에서 영감을 얻은 이 방식은 각 4D 점이 특정 '씨앗(Seed)' 지점에 속할 확률을 계산함으로써 밀도 기반의 클러스터링을 수행한다. 즉, 물체의 중심이 될 가능성이 높인 지점을 찾고, 그 주변의 점들을 확률적으로 묶어 하나의 인스턴스로 정의하는 것이다. 마지막으로 이렇게 생성된 4차원 부분 볼륨(Sub-volumes)들 사이의 겹치는 지점을 분석하여, 시간이 흐름에 따라 인스턴스들의 정체성을 연결하게 된다.
효율적인 4D 볼륨 형성과 메모리 전략
공학적으로 가장 큰 난관은 역시 메모리(Memory) 문제이다. 이론적으로는 모든 과거의 스캔 데이터를 다 쌓아서 처리하면 좋겠지만, 데이터의 양이 늘어날수록 메모리 사용량도 선형적으로 증가하여 시스템이 감당할 수 없게 된다. 이를 해결하기 위해 저자들은 온라인 설정(Online settings)을 도입한다. 차량의 움직임을 보정하기 위해 SLAM 기술에서 제공하는 자기 모션 추정치(Ego-motion estimates)를 사용하여 스캔들을 정렬하고, 특정 시간 윈도우 내의 데이터만 처리하는 방식이다.여기서 저자들의 통찰력이 돋보이는데, 바로 '중요한 것만 골라 담는' 전략이다. 모든 점을 다 저장하는 대신, 시간적 연관성을 유지하는 데 가장 치명적인 역할을 하는 'Thing(객체)' 클래스나 물체 중심 근처에 있는 점들 위주로 과거 스캔에서 샘플링을 수행한다. 이미 이전 프레임에서 한 번 처리된 데이터이기에 무엇이 중요한지 알고 있다는 점을 활용한 것이다. 이러한 영리한 샘플링 덕분에 메모리 효율성을 유지하면서도, 여러 스캔을 동시에 처리함으로써 공간적, 시간적 연관 성능을 획기적으로 높일 수 있었다.
결국 4D-PLS의 핵심은 "어떻게 하면 시공간의 방대한 데이터를 효율적으로 압축하고, 그 안에서 물체의 연속성을 놓치지 않을 것인가"에 대한 해답을 제시한 것이라고 볼 수 있다.
Density Based Clusterting
그렇다면 4차원 공간에서 점들을 어떻게 하나의 '물체(Instance)'로 묶어내는 것일까?
여기서 저자들은 밀도 기반 클러스터링(Density-based Clustering)을 사용한다.지금 현재 다루는 데이터는 단순히 공간에 뿌려진 점들이 아니라 시간이라는 축이 더해진 4차원 정보이기 때문에, 기존의 단순한 거리 방식만으로는 한계가 존재한다. 이를 해결하기 위해 본 논문은 개별 객체 인스턴스를 하나의 가우시안 확률 분포(Gaussian Probability distributions)로 모델링한다.
이 방식의 매력은 물체의 딱딱한 경계를 가진 상자로 보는 것이 아니라, 중심으로부터 퍼져 나가는 확률적인 에너지의 흐름으로 이해한다는 점에 있다. 구체적인 과정을 살펴보면, 먼저 네트워크가 물체의 중심일 가능성이 높은 지점인 '씨앗(Seed)'점을 추정한다. 일단 이 씨앗 점($p_i$)이 결정되면, 그 주변의 다른 점($p_j$)들이 이 씨앗에 속할 확률을 계산하게 된다. 이때 흥미로운 점은 우리가 추정한 중심이 반드시 물체의 물리적 정중앙일 필요는 없다는 것이다. 단순히 클러스터링을 시작하기 위한 시작점 역할을 할 뿐이기에, 물체가 다른 물체 가려지는 폐색(Occlustion) 현상이나 시간이 흐름에 다라 시점이 변하는 상황에서도 시스템은 매우 강건(Robust)하게 작동할 수 있다.
이 확률적 연관성을 수학적으로 정의한 것이 바로 본 논문의 핵심 수식인 가우시안 확률 밀도 함수(Gaussian PDF)이다. 점 $p_j$가 씨안 $p_i$에 속할 확률 $\hat{p_{ij}}$는 다음과 같이 계산된다.

여기서 $e_i$와 $e_j$는 각 점이 가진 임베딩 벡터(Embedding vector)를 의미한다. 임베딩이란 고차원 공간에서 그 점이 가진 특징(Feature)을 숫자로 표현한 것인데, 같은 물체에 속한 점들이라면 이 임베딩 공간에서도 서로 가까운 위치에 존재하도록 학습된다. 또한 수식에 등장하는 $\Sigma_i$는 네트워크가 예측한 분산($\sigma_i$) 값을 대각 성분으로 하는 행렬로, 물체의 크기나 형태에 따라 클러스터링의 범위를 유연하게 조절하는 역할을 한다.
이 연구의 독창성은 여기서 한 걸음 더 나아간다. 단순히 학습된 특징(Embedding)만을 사용하는 것이 아니라, 그 점의 실제 위치 정보인 ($x, y, z$) 좌표와 시간($t$)을 임베딩 벡터에 직접 결합(Concatenate)하여 사용한다. 이렇게 좌표와 특징을 섞어 4차원 시공간 임베딩을 구성함으로써, 네트워크는 공간적으로 가깝고 시간적으로 연속된 점들을 더 정확하게 하나의 인스턴스로 묶을 수 있게 된다. 다만, 물체가 복잡하게 움직이는 상황에서 가우시안 분포라는 가정이 모든 시간대에서 완벽할 수는 없기에, 저자들은 이 가정이 비교적 짧은 시간 윈도우 내에서 가장 유효하다는 점을 명시하며 연구의 정밀함을 더했다.
이러한 밀도 기반의 접근 방식은 복잡한 데이터 연관 알고리즘 없이도 신경망의 출력값만으로 자연스럽게 추적과 분할을 동시에 수행할 수 있게 해준다.
Network and Training
우리가 다루는 4D 포인트 클라우드 $P \in \mathbb{R}^{N \times 4}$로부터 유의미한 정보를 추출하기 위해, 본 모델은 강력한 인코더-디코더 구조를 채택한다. 이 네트워크의 심장부인 인코더는 KPConv 백본을 기반으로 하며, 이는 포인트 클라우드에 직접 '변형 가능한 포인트 컨볼루션(Deformable point convolutions)'을 적용하여 복잡한 3차원 기하 구조를 효과적으로 학습한다. 인코더를 거친 정보는 여러 갈래의 디코더로 전달되어 각각 특화된 작업을 수행한다.가장 먼저 디코더는 점 단위의 특징 임베딩 $\epsilon \in \mathbb{R}^{N \times D}$을 예측하며, 이는 앞서 언급한 클러스터링의 기초가 된다. 이와 동시에 네트워크는 세 가지 추가적인 정보를 병렬로 추출한다. 바로 각 점이 물체의 중심에 얼마나 가까운지를 나타내는 '객체 중심성(Object centerness)', 클러스터링의 범위를 결정할 '포인트 분산(Point Variance)' 그리고 각 점이 어떤 종류인지 분류하는 '의미론적 정보(Semantic posterior)'이다. 이 모든 과정은 온라인 환경에서 엔드 투 엔드(End-to-End) 방식으로 학습되어 시스템의 통합성을 높인다.
네트워크가 우리가 원하는 대로 동작하게 만들기 위해, 저자들은 네 가지 손실 함수를 결합한 $L = L_{class} + L_{obj} + L_{ins} + L_{var}$라는 정교한 학습 목표를 설정했다. 우선 의미론적 분류를 위해 교차 엔트로피 손실($L_{class}$)을 사용하는데, 이때 데이터셋 내의 클래스 불균형 문제를 해결하기 위해 각 클래스의 점들이 균일하게 샘플링되도록 세심하게 조정한다.
객체 중심성을 학습하는 과정에서는 3D 데이터만의 독특한 특성을 고려해야 한다. 이미지와 달리 포인트 클라우드에서는 물체의 정확한 물리적 중심에 점이 존재하지 않는 경우가 많기 때문에, 단순히 중심점을 찾는 대신 각 점 $p_i$와 인스턴스 중심 사이의 유클리드 거리를 정규화한 '객체성(Objectness)' $o_i$를 예측하도록 MSE 손실($L_{obj}$)을 부과한다.

가장 핵심적인 인스턴스 손실($L_{ins}$)은 임베딩 공간에서 같은 물체들이 잘 뭉치도록 유도한다. 이는 우리가 앞서 정의한 가우시안 확률 밀도 함수를 통해 계산된 예측 확률 $\hat{p}{ij}$와 실제 인스턴스 소속 여부인 $p{ij}$ 사이의 차이를 최소화하는 방식이다. 여기에 가우시안 분포의 형태를 안정화하는 분산 평활화 손실($L_{var}$)이 더해져 비로소 견고한 학습 체계가 완성된다.

학습된 네트워크를 실제 데이터에 적용하는 추론 단계는 크게 두 단계로 나뉜다. 첫 번째는 하나의 4D 볼륨 내에서 점들을 묶는 과정이다. 시스템은 먼저 객체성 점수가 가장 높은 점을 씨앗(Seed)으로 선택하고, 가우시안 확률이 0.5보다 큰 모든 점을 해당 클러스터에 할당한 뒤 후보군에서 제거한다. 이 과정을 객체성 점수가 임계값 아래로 떨어질 때까지 반복하여 볼륨 내의 모든 인스턴스를 찾아낸다.
두 번째 단계는 이렇게 처리된 서로 다른 4D 볼륨 사이의 정체성을 연결하는 것이다. 저자들은 연속된 볼륨들 사이에서 겹치는 스캔 데이터를 활용하여, 인스턴스 간의 중첩 점수(Overlap score)를 기반으로 탐욕적(Greedy) 방식의 연결을 수행한다. 만약 중첩 정도가 특정 기준에 미치지 못한다면 해당 물체는 새로운 ID를 부여받게 된다. 이러한 2단계 접근법은 복잡한 데이터 연관 알고리즘 없이도 긴 시간 동인 물체의 정체성을 안정적으로 유지할 수 있게 해준다.
Measuring Performance
이미지 기반의 파놉틱 분할에서는 PQ(Panoptic Quality)라는 지표를 주로 사용하며, 다중 객체 추적 및 분할 분야에서는 MOTSA나 MOTSP와 같은 지표를 활용해왔다. 이들의 공통적인 특징은 '인스턴스 중심(Instance-centric)' 혹은 '세그먼트 중심(Segment-centric)' 평가라는 점이다. 즉, 각 프레임마다 정답(Ground-truth) 객체와 모델이 예측한 결과물을 일대일로 매칭하여, 얼마나 잘 맞았는지(True Positive, TP), 틀렸는지(False Positive, FP) 혹은 놓쳤는지(False Negative, FN)를 결정하는 방식이다.
여기서 PQ는 두 가지 관점에서 성능을 측정한다. 하나는 '분할 품질(SQ, Segmentation Quality)'로, 정답과 예측이 얼마나 정확하게 겹치는지를 의미하는 IoU 값을 TP 세트에 대해 평균 낸 것이다. 다른 하나는 '인식 품질(RQ, Recongnition Quality)'로, 흔히 알려진 F1 스코어를 통해 물체를 얼마나 잘 찾아냈는지를 나타낸다. 한편 추적 지표인 MOTSA는 객체 탐지 오류뿐만 아니라, 추적하던 물체의 번호가 바뀌어버리는 'ID 스위티(IDSW)' 페널티를 하나의 수식에 통합하여 계산한다. 이것이 기존 지표에서 시간적 요소를 고려하는 거의 유일한 벙법이었다.
그러나 이러한 기존 방식들을 LiDAR 데이터에 그대로 적용하기에는 몇 가지 치명적인 문제점이 있다. 우선 PQ는 너무 작은 세그먼트의 중요성을 과도하게 강조하는 경향이 있으며, 경계가 모호한 배경(Stuff) 클래스를 매칭하는 데 어려움이 있다. 또한 MOTSA는 탐지 성능을 연관성능보다 너무 높게 평가하며, 점수가 음수가 될 수 있고, 상한선이 없다는 점에서 직관적이지 못하다는 비판을 받는다. 결정적으로 MOTSA는 프레임 레이트(Frame rate)에 따라 점수가 크게 좌우될 뿐만 아니라, 한번 잘못 연결했다가 나중에 다시 정상을 찾았을 때 이를 보상해주는 체계가 전혀 없다.
가장 큰 기술적 문제는 이 지표들이 '매칭 임계값(Matching threshold)'에 민감하다는 사실이다. 예를 들어 정답과 예측의 겹침 정도가 임계값보다 아주 조금만 낮아도, 이는 동시에 FN과 FP로 처리되어 점수를 깎아먹게 된다. 반면 의미론적 분할(Semantic Segmentation)에서 표준으로 사용하는 mIoU(mean IoU) 지표는 객체 단위의 매칭을 거치지 않고 점(Point)이나 픽셀 단위로 직접 계산하기 때문에 이러한 임계값 문제에서 자유롭다.
최근에는 이러한 PQ 지표를 비디오 영역을 확장하려는 시도들도 있었다. VPQ(Video Panoptic Quality)는 시간적 흐름에 따른 IoU 매칭을 통해 성능을 측정하지만, 짧고 드문드문 레이블링된 비디오 클립에 최적화되어 있어 실제 자율주행 자동차가 마주하는 긴 시간의 연속적인 시퀀스에는 적합하지 않다. 또 다른 확장안인 PTQ(Panoptic Tracking Quality) 역시 MOTA와 PQ를 단순히 결합한 형태라 두 지표가 가진 문제점을 고스란히 물려받고 말았다. 이러한 배경을 통해 저자들은 왜 점 중심(Point-centric)이면서도 시공간을 통합적으로 평가할 수 있는 새로운 지표인 LSTQ를 제안하게 되었는지 그 당위성을 확보하게 된 것이다.
LiDAR Segmentation and Tracking Quality(LSTQ)
해당 지표를 알아보기 전에, 4차원 시공간의 수학적 정의를 알아보자. 저자들은 시간 $l$동안 수집된 3차원 포인트 클라우드 시퀀스를 $\Omega = {(p,n) \in \mathbb{R}^{3} \times \mathbb{N} | n < l}$로 정의한다. 여기서 $p$는 점의 위치인 $(x, y, z)$ 좌표를, $n$은 해당 점이 찍힌 타임스탬프를 의미한다.
이 4차원 튜플을 입력으로 받아 두 가지 함수를 상정한다.
하나는 정답지인 $gt(p,n) \rightarrow (c,id)$이고, 다른 하나는 우리 모델의 예측값인 $pr(p,n) \rightarrow (c,id)$이다.이 함수들은 각 점에 대해 클래스($c$)와 고유 식별 번호($id$)를 부여하는 역할을 한다. LSTQ는 바로 이 개별 점 수준에서 (i) 클래스가 맞았는지, (ii) 객체 인스턴스 ID가 올바른지를 동시에 평가하도록 설계되었다.
LSTQ의 가장 혁신적인 점은 기존 HOTA나 PQ와는 근본적으로 다른 평가 철학을 채택했다는 점이다. 기존 방식들은 '프레임 단위의 탐지(Frame-level detection)'라는 개념에 갇혀 있었다. 즉, 정답 상자와 예측 상자가 얼마나 겹치는지 먼저 계산하고 '매칭'이 되어야만 평가를 시작했다.
하지만 본 논문은 이러한 인위적인 세그먼트 매칭 과정을 과감히 생략한다. 대신 공간과 시간을 하나의 통합된 영역으로 보고, 점 하나하나가 시공간 속에서 올바른 인스턴스에 할당되었는지를 직접 측정한다. 이는 점 데이터의 밀도와 분포가 중요한 LiDAR 세그멘테이션 작업이 훨씬 더 자연스러운 방식이다.
Classification Score
LSTQ는 크게 분류 점수($S_{cls}$)와 연관 점수($S_{assoc}$)라는 두 가지 축으로 구성된다. 먼저 분류 점수는 모델이 각 점의 '정체(Class)'를 얼마나 잘 맞췄는지를 측정한다. 이를 위해 인스턴스 ID를 무시한 채 클래스 $c$에만 집중하는 두 가지 집합을 정의한다.
위 수식에서 "*"은 어떤 ID든 상관없다는 의미이다. 이제 이 두집합을 이용해 우리가 흔히 아는 의미론적 분할의 평가 방식인 *_TP(True Positive), FP(False Positive), FN(False Negative)** 세트를 점 단위로 계산한다.

- $TP_{c}$: 정답도 $c$이고 예측도 $c$인 점들의 수
- $FP_{c}$: 정답은 $c$가 아닌데 모델이 $c$라고 잘못 예측한 점들의 수
- $FN_{c}$: 정답은 $c$인데 모델이 맞추지 못한 점들의 수
결국 분류 점수 $S_{cls}$는 이 세트들을 이용해 각 클래스별 IoU(Intersection-over-Union)를 구하고, 이를 모든 클래스에 대해 평균 내는 mIoU 방식으로 귀결된다.

여기서 중요한 차이점이 발생한다. 기존의 파놉틱 품질(PQ) 지표는 특정 세그먼트가 정답과 충분히 매칭되어야만 그 안의 점들을 TP로 인정해주었지만, LSTQ의 $S_{cls}$는 매칭 여부와 상관없이 '맞은 점은 무조건 맞은 것으로' 처리한다. 덕분에 매칭 임계값에 따른 점수의 요동 없이 모델의 순수한 분류 능력을 측정할 수 있게 된다.
Association Score
분류 점수가 모델의 '언어적 인지 능력'을 평가한다면, 연관 점수(Association Score, $S_{assoc}$)는 모델이 시공간 속에서 물체의 '연속적인 자아'를 얼마나 잘 추적하는지를 평가하는 척도이다. 자율주행 자동차가 도로 위의 다른 차량을 볼 때, 단순히 '저것은 자동차다'라고 아는 것을 넘어 '저 자동차는 1초 전의 그 자동차와 같은 개체다'라는 것을 인식해야 안전한 주행 계획을 세울 수 있기 때문이다.이 Association Score를 계산하기 위해 저자들은 먼저 '의미론적 분류'라는 편견을 잠시 내려놓고 오직 '물체(Thing)'라는 범주에 속하는 인스턴스 ID에만 집중한다. 이를 위해 정답 데이터와 예측 데이터에서 각각 특정 ID를 가진 점들의 집합인 $gt_{id}(id)$와 $pr_{id}(id)$를 정의한다. 이 집합들은 해당 물체가 나타나는 모든 시간대의 점들을 포함하는 하나의 '시공간 튜브(Spatio-temporal tube)'와 같은 형태를 띠게 된다.
여기서 핵심이 되는 세 가지 개념이 등장하는데, 바로 진양성 연관(True Positive Association, TPA), 위양성 연관(False Positive Association, FPA), 그리고 위음성 연관(False Negative Association, FNA)이다.
TPA는 정답 객치 $t$와 에측 객체 $s$가 서로 일치하는 ID를 가진 채 실제로 겹치는 점들의 집합을 의미하며, 수식으로는 $TPA(id, id') = |pr_{id}(id') \cap gt_{id}(id)|$와 같이 표현된다.
반면 FPA는 모델이 특정 ID를 부여했지만 실제로는 다른 객체이거나 아무 물체도 아닌 곳에 찍힌 점들을 나타내고,

FNA는 실제 객체의 점임에도 불구하고 모델이 다른 ID를 주었거나 아예 놓쳐버린 점들을 의미한다.
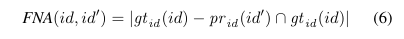
과거의 다중 객체 추적(MOT) 지표들은 정답과 예측 사이에 복잡한 일대일 매칭 과정을 거쳐야 했지만, LSTQ는 모든 계산을 4차원 점 단위에서 직접 수행함으로써 시공간상의 연관성을 훨씬 유연하고 자연스럽게 통합한다.
이제 이 개별적인 연관성들을 하나로 묶어 최종적인 연관 점수 $S_{assoc}$를 산출한다. 예측된 각 세그먼트 $s$가 정답 세그먼트 $t$와 얼마나 잘 일치하는지를 평가하기 위해, 두 세그먼트가 단 하나의 점이라도 겹친다면, 그 기여도를 합산하는 방식을 취한다. 구체적인 수식은 아래와 같다.
$$S_{assoc} = \frac{1}{|T|} \sum_{t \in T} \frac{1}{|gt_{id}(t)|} \sum_{s \in S, s \cap t \neq 0} TPA(s,t) IoU(s,t)$$이 수식에서 주목할 점은 각 기여도를 TPA 세트의 크기에 따라 가중치를 준다는 것이다. 이는 시간이 지나도 오래 유지되는 물체(즉, 시공간적 범위가 넓은 인스턴스)가 전체 점수에 더 큰 영향을 미치도록 설계된 것인데, 이를 통해 모델이 찰나의 순간이 아니라 긴 시간 동안 물체를 놓치지 않고 추적하도록 유도한다.
최종적인 LSTQ 점수는 앞서 계싼한 분류 점수($S_{cls}$)와 이 연관 점수($S_{assoc}$)의 기하 평균(Geometric mean)으로 계산된다. $LSTQ = \sqrt{S_{cls} \times S_{assoc}}$
산술 평균이 아닌 기하 평균을 사용하는 이유는 분류와 연관 중 어느 하나라도 치명적으로 실패하여 점수가 0에 수렴한다면 최종 점수 역시 매우 낮게 나오도록 하기 위함이다. 이는 장면 이해 시스템이 가져야 할 엄격한 안전 기준을 반영한 공학적 결정이라고 할 수 있다.
LSTQ의 또 다른 강력한 장점은 분류 오류와 연관 오류를 분리(Decouple)했다는 것이다. 기존 지표인 MOTSA 등에서 트럭을 버스로 잘못 분류하기만 해도 추적을 아무리 잘했어도 연관 점수까지 깎여버리는 '오류 엉킴' 현상이 있었다. 하지만 LSTQ는 설령 모델이 물체의 종류를 착각했더라도 그 물체를 끝까지 하나의 ID로 잘 쫓아갔다면 연관 점수에서는 정당한 보상을 해준다. 이러한 설계 덕분에 연구자들은 자신의 모델이 인식 능력이 부족한 것인지, 아니면 추적 능력이 부족한 것인지를 훨씬 더 명확하게 진단할 수 있게 되었다.
Experimental Setup
이 논문은 SemanticKITTI라는 유명한 3D LiDAR 데이터셋을 사용하여 자신의 모델이 왜 뛰어난지를 증명한다.
메모리와 성능, 포인트 전파 전략
가장 먼저 다루는 실험은 포인트 전파(Point Propagation) 전략이다. 앞서 언급했듯이 모든 점을 무작정 다 쌓는 것은 메모리 한계 때문에 불가능하다. 그래서 저자들은 과거의 스캔에서 어떤 점들을 골라 현재로 가져올지에 대한 네 가지 전략을 세우고 성능을 비교했다.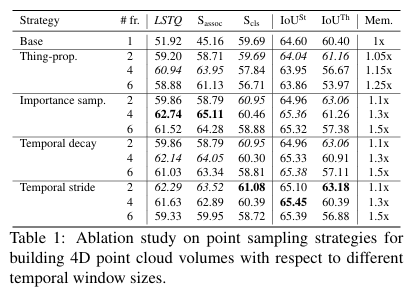
실험 결과, 물체성(Objectness) 점수에 비례하여 전체의 10% 정도를 뽑는 중요도 샘플링(Importance Sampling) 방식이 가장 뛰어난 효율을 보여주었다. 흥미로운 점은 단순히 자동차 같은 'Thing' 클래스만 챙기는 것보다, 도로 같은 배경(Stuff) 점들을 일부 포함하는 것이 결과적으로 전체적인 장면 이해도를 높여 의미론적 분할 기능($S_{cls}$)까지 개선했다는 사실이다. 또한, 단 두개의 스캔만 합쳐도 단일 스캔 대비 성능이 비약적으로 상승하면서도 메모리 사용량은 고작 1.1배 정도만 늘어난다는 결과는 이 방식의 실용성을 아주 잘 보여준다. 연구팀은 최종적으로 시간 윈도우 크기를 4($\tau = 4$)로 설정했을 때가 연관 정확도와 분류 정확도의 가장 완벽한 균형점임을 찾아낸다.
임베딩 설계: 공간, 시간, 그리고 특징의 결합
그 다음으로 중요한 실험은, 점들을 묶어주는 기준인 임베딩 디자인(Embedding Design)에 대한 절제 연구(Ablation Study)이다. 우리는 점의 위치($xyz$), 시간($t$), 그리고 네트워크가 학습한 특징($Emb.$) 중 무엇을 얼마나 섞어야 할까? 아래 표를 보면 그 답이 명확해진다.
단순히 공간 좌표만 쓰거나 학습된 특징만 다로 썼을 때보다, 이 모든 것을 하나로 섞은 'Emb. + xyzt' 조합이 가장 높은 $S_{assoc}$와 $S_{cls}$ 점수를 기록했다. 이는 매우 종요한 통찰을 주는데, 잘 설계된 임베딩 가지(Branch)가 단순히 물체를 묶어주는 역할에 그치지 않고, 네트워크의 등추(Backbone)가 더 유의미한 특징을 학습하도록 돕는 선순환 구조를 만든다는 것을 시사한다.
이제 이 모델과 다른 모델을 비교해보면,
단일 스캔 파놉틱 분할 성능을 보면, 본 연구의 모델은 기존의 강자인 RangeNet++나 KPConv 기반의 다른 조합들을 제치고 모든 지표에서 가장 높은 성적(State-of-the-art)을 거두었다.
4D 파놉틱 분할에서도 결과는 압도적이었다. 기존의 방식들이 단일 프레임 결과를 낸 뒤 칼만 필터(Kalman Filter) 같은 외부 알고리즘으로 억지로 이어 붙이는 '추적 기반 탐지' 패러다임에 머물러 있을 때, 모든 과정을 시공간적으로 통합한 이 논문의 방식은 연관 점수($S_{assoc}$)와 최종 LSTQ 점수 모두에서 경쟁자들을 큰 차이로 따돌렸다. 특히 복잡한 데이터 연관 기술 없이도 단순히 여러 스캔을 겹쳐 처리하는 것만으로 훨씬 더 안정적인 추적이 가능하다는 점은 이 논문이 가진 '시공간 통합 인지' 철학이 얼마나 강력한지를 여실히 보여준다.
Benchmark Results
Single-scan Prediction
연구팀은 가장 먼저 단일 스캔 LiDAR 파놉틱 분할 성능을 평가하며 네트워크의 순수한 공간 인지 능력을 점검했다. 이는 시간 축을 더하기 전, 3차원 공간에서 각 점의 클래스와 객체를 얼마나 잘 구분하는지 확인하는 필수적인 과정이다. 실험 결과, 제안된 모델은 SemanticKITTI 데이터셋의 모든 지표에서 당시 최고 수준(SOTA)의 성적을 거두었다.여기서 주목할 만한 점은 모델의 구조의 효율성이다. 기존의 많은 방식은 객체 탐지와 의미론적 분할을 위해 두 개의 독립된 네트워크를 사용한 뒤 그 결과를 하나로 합치는 번거로운 과정을 거쳤지만, 이 논문의 모델은 단 한번의 네트워크 통과(Single network pass)만으로 이 두가지 동시에 완벽하게 수행해냈다. 또한, RangeNet++처럼 LiDAR 데이터를 이미지 형태로 변환해 처리하는 방식들과 달리, 점 구름(Point Cloud) 그 자체에 KPConv 백본을 직접 적용함으로써 정보의 손실 없이 더 정밀한 인지가 가능함을 입증했다.
4D Panoptic Segmentation
단일 공간에서 승리를 거둔 뒤, 연구는 본격적으로 시간 축이 포한된 4D Panoptic Segmentation 과제로 확장된다. 여기서는 모델의 성능을 비교하기 위해 기존의 단일 프레임 방식들을 두 가지 전략으로 확장하여 대조군을 만들었다. 첫 번째는 등속도 운동 모델을 사용하여 객체의 궤적을 예측하는 AB3DMOT 방식이고, 두 번째는 최신 LiDAR 씬 플로우(Scene Flow) 기술을 이용해 점들을 시간 순서대로 투영하고 묶는 SFP 방식이다.결과는 매우 고무적이다. 분할, 참지, 추적을 하나의 네트워크 안에서 유기적으로 통합한 본 연구의 방식은 모든 '탐지 후 추적(Tracking-by-detection)' 기반의 기준 모델들을 압도적인 차이로 제치고 가장 높은 성능을 기록했다. 특히, 칼만 필터와 같은 정교한 외부 연관 알고맂듬을 사용하지 않고도, 단순히 4차원 시공간 볼륨 내에서 점들을 겹쳐서 처리하는 것 만으로도 훨씬 더 안정적이고 정확한 추적이 가능하다는 점이었다. 이 복잡한 수학적 사후 처리보다 데이터의 시공간적 본질을 직접 학습하는 것이 얼마나 중요한지 보여준다.

MOTSA의 한계와 LSTQ의 통찰

연구팀은 여기서 기존에 널리 쓰이던 MOTSA 지표가 얼마나 비직관적일 수 있는지 지적한다. 구체적인 사례로 2개 스캔을 처리할 때와 4개 스캐을 처리할 때의 결과를 비교해 보면, 이 연구의 LSTQ의 점수는 59.86에서 62.74로 상승하며 성능 향상을 정확히 반영한다. 하지만 놀랍게도 동일한 상황에서 MOTSA 점수는 33.2에서 4.8로 급격히 떨어지는 기현상이 발생한다.
그 원인을 분석해 보니, 이는 추적 자체의 문제라기보다는 특정 클래스(예: 오토바이)에서 발생한 미세한 의미론적 오분류와 정밀도(Precision) 저하 때문이었다. MOTSA는 이러한 분류상의 작은 실수를 추적 성능과 하나로 묶어 처리하기 때문에, 실제로는 물체를 끝까지 잘 쫓아가고 있음에도 불구하고 점수가 심각하게 깎여버리는 부작용이 있었던 것이다. 반면 이 논문에서 제안한 LSTQ는 분류 성능과 연관 성능을 분리하여 평가하므로, 모델이 가진 강점과 약점을 훨씬 더 정확하고 투명하게 진단해준다.
Coclusion
기존에 정적인 상태에 머물러 있던 LiDAR 파놉틱 분할을 시간이라는 새로운 차원으로 확장하여, 4D 파놉틱 분할이라는 새로운 과제를 명확히 정립했다는 점에 있다. 저자들은 단순히 새로운 용어를 만드는 데 그치지 않고, 이 복잡한 시공간적 성능을 정밀하게 측정할 수 있는 새로운 평가지표(LSTQ)와 이를 실제로 구현해낸 혁신적인 모델을 동시에 세상에 내놓았다.
가장 핵심적인 통찰은 '통합'의 힘이다. 이 연구는 의미론적 분할과 점-인스턴스 연관 작업을 시공간 내에서 하나의 모델로 묶어 처리하는 것이, 각각의 작업을 따로 떼어내어 독립적으로 해결하려던 기존의 방식들보다 훨씬 더 압도적이고 강력한 성능을 발휘한다는 사실을 명확하게 증명해냈다.
결국 저자들이 제시한 이 통합적인 시각과 모델, 그리고 모든 연구자가 공정하게 경쟁할 수 있도록 공개된 공공 벤치마크는 이 분야가 다음 단계로 도약하기 위한 튼튼한 이정표가 될 것이다.
'Paper Review > 3D Vision' 카테고리의 다른 글