-
[Paper Review] In Search of a Data Transformation That Accelerates Neural Field(Seo et al., 2024)Paper Review/3D Vision 2026. 2. 3. 13:11
Neural Field(신경장)이란, 기존의 이미지는 픽셀 값들의 행렬(Grid)로 저장되었다면, Neural Field는 "좌표 $(x, y)$를 넣으면 색상 $(R, G, B)$가 나오는 함수" 자체를 신경망으로 학습시키는 방식이다. 이 방식은 고차원 데이터를 아주 세밀하게 표현할 수 있다는 장점이 있어서 3D 장면을 복원하는 NeRF 같은 기술의 핵심이 되었다. 하지만 치명적인 단점이 하나 존재하는데, 바로 데이터를 하나하나 표현할 때마다 신경망을 새로 '과적합(Overfitting)' 시켜야한다는 점이다. 이미지를 한 장 저장하려고 수천 번의 SGD(확률적 경사 하강법) 학습을 거쳐야 하니 시간이 너무 오래걸리게 된다.
이 학습 속도를 늦추는 주범으로 논문은 최적화 편향(Optimization Bias), 그중에서도 스펙트럼 편향(Spetral Bias)을 지목하고 있다. 인공 신경망은 학습할 때 저주파 성분(이미지의 뭉퉁한 배경 등)을 먼저 배우고, 고주파 성분(세밀한 무늬나 경계선)은 나중에 배우려는 성질이 있다. 그래서 자연스러운 이미지의 부드러운 부분은 금방 학습하지만, 정작 중요한 디테일을 잡아내기까지는 엄청난 학습 시간이 소요되게 된다.
기존 연구들은 스펙트럼 편항을 이겨내려고 모델 구조를 복잡하게 만들거나(Fourier features 등), 초기값을 잘 주려는 노력을 했다. 즉, "모델을 똑똑하게 만들어서 고주파를 잘 배우게 하자"는 전략이라고 볼 수 있다.
그런데 이 논문은 아주 도발적인 질문을 던진다. "SGD의 편향을 억지로 고치려 하지 말고, 데이터를 변형해서 그 편향이 우리에게 유리하게 작용하게 만들 순 없을까?" 라는 것이다.
전략은 간단하다.
- 원본 데이터를 어떤 방식($T$)로 변형한다.
- 변형된 데이터를 Neural Field로 학습시킨다.
- 학습된 결과에 역변형($T^{-1}$)을 가해 원본을 복구한다. 이 과정에서 만약 변형된 데이터가 원본보다 훨씬 빨리 학습된다면, 전체적인 학습 시간을 획기적으로 줄일 수 있다는 계산이다.
연구팀은 픽셀의 위치를 섞거나 강도를 조절하는 등 7가지 변형을 실험했다. 그 결과 무작위 픽셀 위치 변경(Random Pixel Permutation, RPP)이 모든 환경에서 일관되게 학습 속도를 높인다는 사실을 발견했다. 평균적으로 원본보다 약 30%나 더 빨리 원하는 품질에 도달했다고 한다.
상식적으로 픽셀을 무작위로 섞으면 이미지가 노이즈처럼 변해서 더 배우기 힘들 것 같다고 생각하지만, 결과는 정반대였던 것이다. 그렇다면 왜 이런 현상이 발생할까? 저자들은 이를 easy-to-fit patterns으로, 쉬운 패턴의 역설로 설명을 한다.
- 원본 데이터 : 인접한 픽셀끼리 비슷비슷한 '부드러운 패턴'이 있다. 학습 초기에는 이게 도움이 되는 것 같지만, 나중에 아주 정밀한 디테일을 배워야 할 단계가 오면, 이 부드러운 패턴들이 오히려 방해 요소가 되어 최적화를 더디게 만든다.
- RPP 데이터 : 처음부터 픽셀을 섞어버리니 '쉬운 패턴'이 아예 사라진다. 그래서 초기 학습은 원본보다 조금 느릴 수 있지만, 일단 어느 정도 궤도에 오르면 Linear Loss Highway라고 부를 만큼 최적화가 아주 매끄럽고 빠르게 진행된다는 것이다.
이 논문의 공헌은 크게 다음 세 가지이다.
- 데이터 변형만으로 학습 속도를 0.1배에서 최대 20배까지 드라마틱하게 바꿀 수 있음을 보여준다.
- 특히 RPP가 다양한 아키텍처에서 안정적인 가속(x1.08 ~ x1.5)을 제공한다는 걸 발견했다.
- 이런 현상의 발생 이유에 대해 Loss Landscape와 Error pattern 분석을 통해 심도 있게 파헤쳤다.
General Framework
그렇다면 "데이터를 어떻게 변형할 것인가?" 다음을 살펴보자.
1. Formalisms
저자들은 해결하려는 문제를 아주 명확한 수식으로 정의헀다.
먼저 우리가 근사하고 싶은 신호를 $x$ (예: $256 \times 256$ 크기의 RGB 이미지)라고 하자. 여기서 적용할 변형을 $T$라고 부른다. 이 $T$는 원본 이미지를 다른 형태로 바꾸는 함수이다.
$$
\text{cost}(x,T)
$$
먼저 위 수식은 현재 달성하고자 하는 목표(Objective)이다. 보통 모델의 정확도를 높이는 데 집중하지만, 이 논문은 그 정확도에 도달하기까지 얼마나 고생하는지(Computational Burden)를 최소화하고 싶어한다.즉, 위 목표, 비용 함수(cost)의 의미는 변형 $T$를 적용한 데이터를 신경망이 학습해서, 다시 역변환($T^{-1}$)했을 때, 우리가 원하는 정밀도, 혹은 SGD 스텝 수를 의미한다.
단순히 "변형된 이미지를 잘 배우는가?"가 아니라, 변형된 이미지를 배워서 원본으로 돌려놨을 때의 결과가 기준이라는 점이 중요하다. 그래야 실질적인 데이터 저장/복원 관점에서 공정한 비교가 되기 때문이다.
$$
\text{cost}(x, T) \neq \text{cost}(T(x), \text{Id})
$$
위 수식은 "변형 $T$를 거친 $x$를 학습시키는 비용"이 "그냥 변형된 데이터 그 자체를 학습시키는 비용"과 같지 않다는 의미이다.왜 그럴까? 예를 들어 이미지를 밝게 만드는 선형 스케일링(Linear Scaling)을 한다고 해보자. 픽셀 값들이 커지면서 손실 함수(Loss)의 기울기(Gradient)도 커지게 된다. 그러면 SGD가 더 성큼성큼 움직이게 되고, 겉으로 보기엔 학습이 빨라진 것처럼 보일 수 있다. 하지만 이건 '데이터의 본질'이 쉬워진게 아니라 단순히 '보폭'이 커진 것뿐이다. 논문은 이런 수치적인 착시 현상을 경계하고 있다. 그래서 반드시 역변환 후의 품질을 기준으로 비용을 측정해야 한다고 강조한다.
결국 이 연구가 풀고자 하는 문제는 아래와 같다.
$$\text{minimize } \text{cost}(x, T) \quad \text{subject to } T \in T^*$$여기서 $T^{*}$는 역함수가 존재하고 계산이 효율적인 변형들의 집합이다. 아무리 학습이 빨라져도 픽셀 위치를 복구하는 데 한 세월이 걸린다면 Neural Field를 쓰는 의미가 없을 것이다. 그래서 논문은 계산이 매우 빠르면서도 학습을 가속화할 수 있는 최적의 $T$를 찾으려 하는 것이다.

논문에서는 총 7가지의 데이터 변형 후보를 제시한다.위 7가지 변형은 데이터의 분포를 두 가지 방식으로 건드린다.
- 위치 변형(Permutation) : 픽셀의 물리적 위치를 바꿈으로써 이미지의 공간적 주파수(Spatial Frequency)를 완전히 뒤흔들어버린다. RPP(무작위 섞기)가 여기에 해당하는데, 이는 이미지의 기하학적 구조를 파괴해서 SGD가 초반에 '쉬운 패턴'에 안주하지 못하게 만든다.
- 값 변형(Intensity) : 픽셀 값의 동적 범위(Dynamic Range)나 분포르 바꾼다. 표준화(Standardization)나 감마 보정(Gamma)이 여기에 해당한다. 이건 손실 함수의 지형(Loss Landscape)을 더 둥글고 예쁘게 만들어서 SGD가 길을 잘 찾게 도와주려는 시도이다.
하지만 논문은 앞서 세운 수학적 Framework가 이론적으로는 완벽하나, 현실적으로느느 풀기 매우 어려운 문제(Intractable)라는 점을 솔직하게 인정하고 있다.
현재 찾는 최적의 변형 $T$는 마치 모든 가능한 퍼즐 조각의 조합 중에서 가장 맞추기 쉬운 조합을 찾으라는 것과 같다. 즉, 변형의 가짓수가 무한대에 가깝기 때문에, 이를 수학적으로 한 번에 계산해서 "이게 정답이다!"라과 내놓을 수 있는 최적화 방법이 아직 없다는 의미이다.
그래서 저자들은 영리한 우회 전략을 택한다. 바로 개념 증명(Proof-of-concept)이다.
$$\text{cost}(x, T) < \text{cost}(x, \text{Id})$$복잡한 알고리즘을 짜서 최적의 $T$를 찾아내진 못하더라도, 적어도 우리가 제안하는 특정 $T$를 쓰면, 아무것도 안 했을 때보다 확실히 학습 비용이 적게 든다는 사실을 실험으로 입증하겠다는 것이다.
2. Example Cases
그렇다면 위 수식으로 정의한 프레임워크를 바탕으로, 실제로 어떤 조건을 만족하는 데이터 변형($T$)이 좋은가?에 대한 구체적인 사례들을 살펴보자.
Efficient Invertibility
우리가 데이터를 변행해서 학습시켰다면, 나중에 모델을 쓸 때는 당연히 원래 데이터로 돌려놔야한다. 이때 역변환($T^{-1}$)을 계산하는데 시간이 너무 오래 걸리면, 학습 속도를 줄여서 얻은 이득을 다 까먹게 될 것이다.
논문은 이때 아이디어를 제시한다. "역변환 과정을 아예 신경망의 파라미터 안에 녹여버릴 수 있다면?"
- 예를 들어, 만약 우리가 모든 픽셀 값에 마이너스를 곱하는 변형($T(x) = -x$)을 줬다고 해보자. 학습이 끝난 뒤에 결과물에 일일이 마이너스를 다시 곱하는 대신, 신경망의 마지막 레이어 가중치(Weights)에 -1을 미리 곱하면 된다.
- 이렇게 하면 추론(Inference) 단계에서 추가 연산이 전혀 필요 없다. 실시간 상호작용이 중요한 애플리케이션에서는 이 '파라미터 직접 수정' 방식이 엄청난 장점이 된다.
Retains Interpolatability
Neural Field의 가장 큰 매력 중 하나는 픽셀과 픽셀 사이의 값, 즉 연속적인 좌표에 대한 값을 알아낼 수 있다는 것이다. 이걸 보간(Interpolation)이라고 한다.
초해상도(Super-Resolution) 작업의 경우 저해상도 이미지를 학습시킨 뒤, 그 사이사이 좌표값을 모델에게 물어봐서 고해상도 이미지를 만들어낸다. 이런 경우에는 데이터를 변형하더라도 좌표 간의 연속적인 관계가 깨지면 안된다.
반면, 데이터 압축(Data Compression) 같은 경우에는 정해진 픽셀 위치의 값만 정확히 복원하면 되니깐, 픽셀을 무작위로 섞어버리는 RPP 같은 변형을 써도 아무런 문제가 없다.
즉, 현재 논문에서 이야기 하고 있는 RPP(Random Pixel Permutation)을 위 두 가지 기준들에 대해 대입해보면,
역변환성 : 픽셀 위치를 섞는 것은 인덱스(Index) 매핑 테이블만 가지고 있으면 아주 쉽게 되돌릴 수 있다. 비록 신경망 가중치 안에 직접 녹이기는 어렵지만, 인덱싱 연산 자체는 매우 가볍다.
보간 가능성 : RPP는 공간적인 구조를 완전히 파괴해버린다. 옆에 있던 픽셀이 저 멀리 가버리기 때무이다. 그래서 보간이 필요한 초해상도 작업에는 적합하지 않다. 하지만 논문이 타겟으로 삼는 데이터 압축 같은 분야에서는 최적의 효율을 보여줄 수 있는 것이다.
Data transformations vs Training Speed
이제 위에서 정의한 다양한 데이터 변환 방식에 대해 Neural Field 학습 비용을 비교해보자.
Experimental Setup & Results
논문 저자들은 실험의 신뢰도를 높이기 위해 아주 꼼꼼한 설정을 준비했다.
- 목표(Metric) : PSNR 50dB(거의 완벽한 복구 수준)에 도달할 때까지 걸리는 SGD 스텝 수를 측정했다.
- 모델 선정 : 전통적인 강자인 SIREN(주기 함수 활용)과 최신 기술인 Instant-NGP 두 가지를 사용해 범용성을 확인했다.
- 학습 최적화 : 각 변형(T)마다 가장 잘 맞는 학습률(Learning Rate)를 그리드 서치로 새로 찾았다.
Acceleration Factor
학습 속도를 비교하기 위해 아래와 같은 수식을 사용한다.$$\text{acc}(x, T) = \frac{\text{cost}(x, \text{Id})}{\text{cost}(x, T)}$$
값이 1보다 크면 가속(Speed up)이 되었다는 의미이고, 1보다 작으면 오히려 느려졌다는 의미이다.

위 Table1을 보면 결과는 꽤나 충격적이다. 7가지 변형 중 모든 데이터셋과 모든 모델에서 유일하게 일관된 가속을 보여준 것은 오직 RPP(Random Pixel Permutation)뿐이었다.
- RPP의 성적 : SIREN에서는 약 1.08 ~ 1.3배, Instant-NGP에서는 1.32 ~ 1.5배의 가속을 보여준다. 특히 복잡한 구조를 가진 Instant-NGP에서도 성능 향상이 크다는 점이 안상적이었다.
- Zigzag 변형 대실패 : 픽셀을 밝기 순으로 정렬해 아주 부드러운 저주파 이미지를 만든 Zigzag는 SIREN에서 속도가 약 17~21배나 느려졌다. "부드러운 데이터가 학습하기 좋을 것"이라는 직관이 Neural Field에서는 완전히 틀렸다는 걸 보여준다.
- 값 변형(Intensity)의 불확실성 : Standardization이나 Linear Scaling 같은 방식은 모델이나 데이터셋에 따라 빨라지기도 하고 훨씬 느려지기도 한다. 즉, 안정적인 최적화 기법이 될 수 없다는 의미이다.
실험 결과가 시사하는 바는 명확하다. Neural Field의 학습 속도를 결정하는 핵심은 픽셀 값의 수치적 분포보다, 데이터가 가진 공간적 패턴(Spatial Pattern)이라는 의미이다.
우리는 보통 딥러닝에서 데이터가 매끄럽고(Smooth) 노이즈가 없어야 잘 배울 것이라고 생각할 것이다. 그런데 이 논문은 너무 매끄러운 데이터는 SGD를 나태하게 만들어서 오히려 세밀한 디테일 학습을 방해한다.는 역설적인 진실을 수치로 보여준다.
A Closer look at the random permutation
그렇다면, 왜 상식적으로 더 복잡해 보이는 RPP가 학습을 가속하는가?
스펙트럼 편향(Spectral Bias) 이론에 따르면, 신경망은 저주파(부드러운 구조)를 먼저 배우고 고주파(세밀한 노이즈)를 나중에 배운다. 그런데 픽셀을 무작위로 섞은 RPP 이미지는 시각적으로나 수학적으로나(DCT 계수 분석 결과) 고주파 성분이 많다. 이론대로라면 RPP는 원본보다 훨씬 느리게 학습되어야 정상이다.

위 결과를 보면 재미있는 현상이 나타난다.
- 저해상도 단계(PSNR 30dB) : 원본 이미지는 평균 105스텝 만에 도달하지만, RPP는 851 스텝이나 걸린다. 즉, 초반에는 원본이 압도적으로 빠르다.
- 고해상도 단계(PSNR 50dB) : 그런데 목표치가 높아지면 상황이 반전된다. 원본 30dB에서 50dB로 가는 데 엄청나게 고전하며 총 1371 스텝을 쓰지만, RPP는 30db에 늦게 도착했음에도 불구하고 그 이후부터는 단 250스텝 만에 50dB를 찍어버린다.
이건 마치 원본 이미지는 배우기 쉬운 패턴 때문에 초반에 신나게 달리다가 디테일 단계에서 늪에 빠지는 꼴이고, RPP는 초반엔 고생하지만 일단 길을 잡으면 고속도로를 타는 꼴이라고 볼 수 있다.
그렇다면 왜 RPP는 후반부에 급가속이 가능할까?
저자들은 손실지형(Loss Landscape)을 분석했다. 원본 이미지의 경우, 학습 후반부로 갈수록 손실 지형이 매우 복잡하고 구불구불해져서 SGD가 최적의 지점을 찾기 위해 갈팡질팡하게 된다.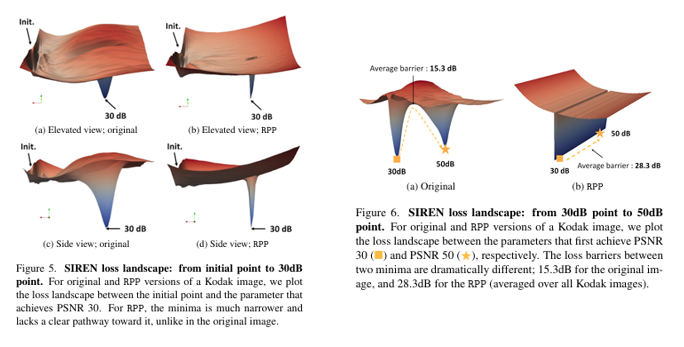
반면, RPP는 놀랍게도 30dB 지점에서 50dB 지점까지 거의 직선에 가까운 매끄러운 경로(Linear path)가 존재한다는 것을 발견했다. 즉, RPP로 데이터를 섞어버리면 신경망이 '가짜 패턴'에 현혹되지 않고, 오직 데이터의 본질적인 값들을 찾아가는 아주 깨끗한 최적화 경로가 형성된다는 의미이다. 저자들은 이를 "패턴이 없는 것이 주는 축복(Blessings of no pattern)"이라고 부른다.
마지막으로 에러(정답과 모델 출력의 차이)의 형태를 살펴봤다.

- 원본 학습 : 에러를 시각화해보면 특정 줄무늬나 격자무늬 같은 '구조적인 패턴'이 나타난다. 이건 신경망이나 인코딩 방식(Grid encoding 등)이 가진 고유의 편향이 결과물에 잔상처럼 남는 것이다. 이 잔상을 지우고 디테일을 채우느라 시간이 오래걸리는 것이다.
- RPP 학습 : 에러가 아주 고르게 퍼진 화이트 노이즈 형태를 띈다. 모델이 특정 위치의 구조적 특징에 편향되지 않고 모든 픽셀을 공평하게 학습했다는 의미이다.
즉, 우리가 흔히 '데이터의 구조'라고 부르는 것들이, 사실은 최적화 관점에서는 SGD를 잘못된 길로 유도하는 '노이즈'로 작용할 수 있다는 점이다.
자연 이미지의 부드러운 구간(패턴)은 학습 초기에 손실 값을 확 낮춰주니깐 기분이 좋지만, 사실 그건 모델이 "대충 비슷하게" 때려 맞추는 법을 배우는 과정이다. 이 '대충' 배운 습관이 나중에 진짜 정밀한 디테일을 배워야할 때 발목을 잡는 것이다. RPP는 처음부터 이 '대충' 배울 기회를 박탈함으로써, 모델이 정석대로 정밀하게 학습하도록 강제하는 효과를 내는 것이다.
Conclusion
이 논문의 가장 큰 수확은 우리가 막연히 믿어왔던 "부드럽고 구조적인 데이터가 학습에 좋다"는 상식을 Neural Field 영역에서 깨버렸다는 점이다. 픽셀을 무작위로 섞어버리는 RPP(Random Pixel Permutation)가 오히려 학습 속도를 30% 이상 앞당긴다는 사실은, 모델 구조나 알고리즘을 건드리지 않고도 데이터의 입력 형태 만으로 최적화 효율을 극적으로 바꿀 수 있음을 시사한다.
Blessings of No Pattern이란 것이 RPP의 경우 초반에 고전을 좀 하지만, 학습 후반부에 Linear Loss highway를 만들어내어, 복잡한 구조적 편향이 제거된 덕분에 SGD가 더 정밀한 최적화 지점으로 거침없이 달려갈 수 있게 되는 것이다.
결국 이 논문은 최적화의 적은 데이터의 복잡함이 아니라, 모델을 나태하게 만드는 '가짜 쉬운 패턴'일 수 있다는 철학적인 결론을 내리는 것 같다.
현재 나는 Quantization 관련해서 연구를 하고 있는 중인데, 해당 논문을 읽어보면서 Quantization에서도 적용될만한 질문이 몇가지 생각이 난 것 같다. 양자화 오차는 보통 데이터의 특정 패턴이나 분포에 따라 특정 레이어에 집중되곤 한다. 만약 여기서 RPP의 원리를 응용해, 양자화 전에 데이터나 활성화 값의 패턴을 의도적으로 분산(Permutation)시킨다면 어떻게 될까? 뭔가 특정 구간에 몰리던 양자화 오차가 전체적으로 균일하게 퍼지면서, 결과적으로 복원 품질을 높이거나 양자화 난이도를 낮추는 효과를 볼 수도 있을 것 같다. 한번 실험 해봐야겠다:)
'Paper Review > 3D Vision' 카테고리의 다른 글